Эта статья опубликована под лицензией Creative Commons и не автором статьи. Поэтому если вы найдете какие-либо неточности, вы можете исправить их, обновив статью.

Большие данные и законодательство о конкуренции



Ючинсон К. С.
Опубликована Янв. 1, 2017
Последнее обновление статьи Июнь 4, 2023
Эта статья опубликована под лицензией
")



Аннотация
Расширение доступа к сети Интернет в глобальном масштабе и кратный рост вычислительных мощностей привели к распространению бизнес-моделей, строящихся на сборе и обработке массивовданных — «Big Data». С развитием интеллектуального анализа данных и машинного обучения компании могут предлагать потребителям решения под их индивидуальные потребности и обратную связь с пользователями. Передовые алгоритмы самообучения позволяют найти точную искомую информацию при онлайн-поиске в кратчайшее время. Однако наряду с огромными преимуществами использование Больших Данных имеет и серьезные недостатки. Недавние громкие сделки слияния и поглощения на цифровых и Интернет-рынках подняли вопрос о воздействии объединения иприобретения контроля над большими массивами данных на конкуренцию. Действительно, компании могут использовать передовые компьютерные технологии для координации деловых практик, навязывания потребителям неправомерных условий, использования расширения рыночной власти для повышения цен и даже для возможного закрытия рынка для новых конкурентов. Сетевые эффекты на основе данных проявляют тенденцию к устойчивости, что позволяет действующим участникам рынка закрепить свои позиции, как только будет достигнута критическая масса пользователей. Компенсируют ли преимущества Больших Данных общественные издержки, зависит втом числе от того, как антимонопольные органы и регуляторы будут реагировать на новые вызовы цифровой экономики. Либо будут формироваться все более конкурентные, состязательные и динамично развивающиеся рынки, где преобладают эффективность и инновации; либо последует экономическая концентрация, ведущая к злоупотреблениям рыночной властью и к стагнации. В статье предлагается определение «Больших Данных» и описываются основные типы воздействующих субъектов и топология рынка «экосистемы Больших Данных». Выявлены возможные конкурентные проблемы в связи с использованием Больших Данных и проанализировано их потенциальное воздействие на результативность инструментов содействия конкуренции и на основные направления работы антимонопольных органов: борьбу с картелями, оценку злоупотребления доминированиеми контроль над слияниями.
Ключевые слова
Цифровая экономика, Интернет, конкуренция, Большие данные, сделки слияния, потребитель, злоупотребление доминирующим положением, законодательство о конкуренции, цифровые картели, рыночная власть
Введение
В настоящее время во многих частях света можно получить подробные навигационные указания об условиях трафика в реальном масштабе времени; прогнозирование и купирование эпидемий в короткий срок, потенциально спасающее миллионы жизней. Наращивается эффективность электронных торговых площадок, где цены корректируются согласно спросу/предложению практически в режиме реального времени, когда потребители извлекают преимущества от индивидуализированных предложений и обратной связи с пользователями. Социальные и профессиональные сети позволяют поддерживать контакты с друзьями и коллегами или находить партнеров; передовые алгоритмы самообразования помогают находить точную информацию с минимальными временными затратами через Интернет-поиск.
Это только некоторые достижения Больших Данных, под которыми часто понимаются: (1) большие объемы массивов данных; и (2) потребность в использовании крупномасштабных вычислительных мощностей и нестандартного программного обеспечения и методов извлечения ценности из данных в разумные сроки. Благодаря возможностям сбора и обработки данных, сегодня бизнес может узнать не только адреса пользователей (неважно, физический или IP-адрес), дату рождения и пол, но и множество другой информации (состав семьи, привычки питания, данные о совершенных ранее покупках, частота и продолжительность посещений традиционных и Интернет-магазинов), а также получить информацию из других баз данных, чтобы сформировать досье на потребителя1. Это позволит ритейл-бизнесу не только дифференцировать цены, но также целенаправленно рассылать потребителям маркетинговые и рекламные материалы, чтобы влиять на их поведение.
Тем не менее кроме значительных выгод Большие Данные несут с собой издержки. Потребители все больше сталкиваются с проблемой утраты контроля над персональными данными и конфиденциальностью; с назойливой рекламой и дискриминацией поведения и оказываются еще сильнее «привязанными» к услугам, которыми обычно пользуются.
Многие наблюдатели рассматривают сбор, обработку и использование персональных данных для коммерческих целей скорее в качестве проблемы защиты потребителей, чем контролирования исполнения законодательства о конкуренции. Однако недавние громкие слияния и поглощения на цифровых или Интернет-рынках заставляют задуматься о возможном влиянии соединения воедино и получения контроля над большими массивами данных на конкуренцию. Действительно, фирмы используют передовые компьютерные технологии для координации деятельности, навязывания условий, противоречащих интересам потребителей, применения рыночной власти для повышения цен и даже закрытия рынка перед потенциальными конкурентами. Сетевые эффекты с управлением данными демонстрируют тенденцию к устойчивости и являются само- поддерживающимися. Они дают преимущества участникам рынка, способствуя дальнейшему укреплению их позиций, как только будет достигнут переломный момент в накоплении критической массы пользователей.
Превысят ли преимущества Больших Данных их общественные издержки, зависит, в частности, от того, смогут ли антимонопольные органы и регуляторы реагировать на новые вызовы цифровой экономики, и как они это сделают. Исходя из этого, рынки либо будут становиться все более конкурентными, состязательными и динамичными, и на первый план выйдут эффективность и непрерывные инновации; либо будет наблюдаться усиление экономической концентрации, приводящее к злоупотреблению рыночной властью и стагнации.
Проблемы г области конкуренции, связанные с Большими Данными
А) Понятие «Больших Данных» и основные субъекты «экосистемы Больших Данных»
1) Определение
Хотя термин «Большие Данные» нередко понимается неточно, чаще всего используется следующее определение: «Большие Данные — информационные активы столь большого объема, скорости передачи и разнообразия, что требуются особые технологии и аналитические методы для их преобразования с целью получения ценности»2. Чтобы отграничить Большие Данные от данных в целом, предлагается следовать подходу Штюке и Грюнса3. К определению «3 V», впервые введенному Лейни4: объем данных (volume); скорость сбора, использования и распространения (velosity); разнообразие сводной информации (variety); Штюке и Грюнс добавили четвертое «V» — ценность данных (value). Как сказано ими о персональных данных, за последнее десятилетие каждый из четырех элементов невероятно расширился и продолжает расширяться.
Ожидается, что объем данных, обрабатываемых в мировом масштабе, растет практически по экспоненте. Американская технологическая компания Cisco прогнозирует, что к концу 2019 г. ежегодный мировой трафик IP-данных достигнет 10,4 секстибайт (ZB)5 по сравнению с 3,4 секстибайт в год в 2014 г., что составляет 25%-й совокупный темп годового прироста с 2014 г. по 2019 гг.6 Такой объем является следствием повсеместного распространении сетевых и Интернет-операций.
ОЭСР7 подчеркивает, что практически все средства массовой информации и социально-экономические операции перетекают в Интернет (включая электронную торговлю и «электронное правительство»); таким образом, каждую секунду формируются петабайты данных. Росту объема данных способствует актуализация закона Мура (Moore’s Law)8, по которому еще более мощные, меньшего размера, более интеллектуальные и менее дорогие устройства стали доступными почти любому индивиду. В свою очередь, это привело к сокращению издержек сбора, обработки и анализа данных. Одновременно доступ к данным облегчается распространением Интернет-платформ, электронной торговли и популярности смартфонов.
Штюке и Грюнс указывают, что в настоящий момент скорость доступа, переработки и анализа данных у некоторых компаний приближается к реальному времени. Способность использовать данные в режиме реального времени — явление, известное как «наукастинг» (Вставка 1).
Наукастинг (Now-casting) (сверхкраткосрочное прогнозирование)
Бандура и др. определяют наукастинг как «прогнозирование настоящего, ближайшего будущего и самого недавнего прошлого»9. Заключается в использовании новых, обновленных и высокочастотных данных для получения опережающих оценок, как правило, с большой степенью точности, о событиях, происходящих практически в настоящее время. Сверхкраткосрочное прогнозирование особенно полезно для получения информации в режиме, близком к реальному времени, о соответствующих переменных, обычно собираемой с низкой частотой и публикуемой позже. Бандура и др.10 показывают, как статистическую модель сверхкраткосрочного прогнозирования, публикуемую ежемесячно с небольшой задержкой, можно использовать в промышленном производстве для точной и опережающей оценки ВВП еврозоны. Обычно такие оценки выходят ежеквартально с 6-недельным отставанием. Концепции наукастинга уже давно придерживаются метеорологи, используя совокупность новейших данных, получаемых с радаров, спутников и путем наблюдений, для описания с большой степенью точности погодных условий и их ожидаемых изменений в ближайшие часы. Развитие методологии наукастинга в метеорологии помогло снизить количество смертей и нанесения ущерба имуществу в результате опасных метеоявлений и повысить безопасность и эффективность некоторых секторов, включая авиацию, управление водными- и энергоресурсами и строительство. В последнее время все больше компаний, использующих Большие Данные, расширяют использование наукастинга на практике. Так, на интерактивной площадке по продаже недвижимости Auction.com запущена система наукастинга по недвижимости, генерирующая отчеты в режиме реального времени о продажах жилья в США, которая в дальнейшем будет использована при расчете ценовых тенденций и других событий. С этой целью Auction.com реализует модели данных, разработанные главным экономистом Google Х.Варьяном, которые строятся на совокупности частных массивов данных промышленного значения и общедоступных данных, найденных в Google. Данные фирмы также позволяют прогнозировать рыночные тренды в режиме реального времени в секторах продажи автомашин, розничной торговли и туризма). Варьян в видео-обзоре системы сверхкраткосрочного прогнозирования Auction.com для рынка недвижимости утверждает: «Системы наукастинга — значительный поворот в современных методах прогнозного анализа рынка. Большинство правительственных и отраслевых отчетов по таким вопросам, как жилье, занятость и расчеты с потребителями публикуются через недели и даже месяцы после рассматриваемых продаж или действий. Для компаний, пытающихся определить состояние рынка и тенденции его развития, это все равно что ехать вперед, смотря в зеркало заднего обзора... Я полагаю, что инвесторы в недвижимость, финансовые институты, правительственные организации и пр. должны внимательно изучить подобные системы наукастинга в плане возможностей более своевременных и точных прогнозов»11.
Концепция такого прогнозирования состоит в обращении к протекающему в данный момент событию и использованию для прогнозирования явлений по мере их осуществления, например, выявление вспышки гриппа благодаря бурному росту онлайн-поисков лекарств против гриппа. Такой подход можно применять для обнаружения потенциальных конкурентов, определив количество загрузок из магазина приложений и затем сопоставив с использованием в онлайн-режиме или предпочтениями поиска. Применение «наукастинга» может дать действующему участнику рынка рычаги влияния на новых игроков.
Таким образом, складывается новое различие между Большими и традиционными данными: значение времени. Способность обработки объемных массивов данных в режиме реального времени формирует неотъемлемую ценность, более важную в ряде случаев, чем получение данных с временным интервалом, например, при оценке информации о движении транспорта в приложениях к дорожной карте.
Разнообразие данных также повысилось благодаря возможностям сбора и переработки, в результате компании знают не только адрес потребителей (физический или IP), дату рождения и пол, но и множество другой информации (состав семьи, привычки питания, данные о совершенных ранее покупках, частота и продолжительность посещений традиционных и Интернет-магазинов), а также информацию из других баз данных, чтобы сформировать досье на потребителя. Это позволит ритейл-бизнесу не только дифференцировать цены, но также целенаправленно рассылать потребителям маркетинговые и рекламные материалы, чтобы влиять на их поведение.
Антимонопольные органы Франции и ФРГ подчеркивают, что изменение потребительских привычек в сторону максимизации пользования Интернетом для всевозможных целей — от покупок до чтения новостей, просмотра фильмов и размещения видеороликов о самих себе — позволяет компаниям «настолько точно регистрировать действия [большой части населения], что можно делать подробные и индивидуализированные выводы о восприимчивости их к коммерческим обращениям»12. Мелькающая реклама из триллера «Особое мнение» (2002), когда по скану радужной оболочки можно установить личность человека и затем срочно передать ему персонализированные рекламные сообщения, уже не является фантастикой.
Данный пример иллюстрирует важность синтеза данных: большие массивы данных сливаются воедино, из них извлекается информация и в совокупности формируется новая информация, благодаря которой продавцы или конкуренты могут лучше понять рынок и работать на нем. Иногда потенциал синтеза данных можно разрабатывать далее, комбинируя персональные данные с другими типами данных (погодные условия, публичные мероприятия, материально-производственные запасы или даже данные о компонентах автомобиля, собранные для выявления износа).
Ценность Больших Данных является одновременно причиной и следствием увеличения объема, разнообразия и скорости. Хотя сами по себе данные могут считаться «бесплатными» (в зависимости от метода сбора), однако процесс извлечения информации из данных генерирует ценность. Антимонопольные органы Франции и ФРГ дружно указывают на «развитие новых методов, с помощью которых можно извлекать ценную информацию из больших массивов (часто неструктурированных) данных»13. ОЭСР определяет аналитику данных как «технические средства получения аналитических оценок и средств расширения возможностей для лучшего понимания, влияния или контролирования информационных объектов специальных знаний (например, природные явления, социальные системы, индивидуумы)»14.
Штюке и Грюнс15 подчеркивают, что Большие Данные тесно связаны с тем, что называют «Большой аналитикой» и явлением, известным как «технологии углубленного изучения»: компьютеры обучаются решать проблемы, спрессовывая большие базы данных путем использования передовых алгоритмов и нейросетей, все больше напоминающих человеческий мозг. Одним из таких примеров является «Проект Рубикон» — широкая интерактивная платформа для автоматизации покупки-продажи рекламы: «Благодаря упорному стремлению к инновациям в результате проекта разработана одна из крупнейших систем вычислений в режиме реального времени с облачными технологиями и большими данными — в тысячные доли секунды обрабатываются триллионы транзакций ежемесячно»16. Как заявляет компания, «по мере обработки большего объема на нашей автоматизированной платформе мы аккумулируем больше данных, например, о ценах, о географических характеристиках и предпочтениях, данные о том, каким образом лучше всего оптимизировать доходы продавцов. Дополнительные данные помогают сделать наши алгоритмы машинного обучения умнее, что повышает результативность подбора покупателей и продавцов. Наша платформа становится привлекательной для большего количества покупателей и продавцов, от которых мы получаем больше данных, что только усиливает эффект сетевой выгоды...»17.
Данная цитата акцентирует не только способ выявления ценности Больших Данных, но также важность интерактивных платформ и сетевого эффекта в рамках «экосистемы Больших Данных». Углубленное или машинное обучение являются ключевыми элементами процесса. Штюке и Грюнс18 верно замечают, что объем и разнообразие данных позволяют фирмам время от времени раскрывать взаимосвязи на основе больших неструктурированных массивов данных, что может оказаться более результативным, чем поиск информации из более четких массивов данных, но меньшего объема. Здесь не только вопрос о наличии выполняемого алгоритма; речь идет также о том, что, казалось бы, разрозненные массивы данных можно подвергать синтезу и извлекать из них информацию, которая иначе не была бы полезной; например, страховая компания может выявить предрасположенности клиента (к рискованным действиям).
2) Основные субъекты и топология рынка «экосистемы Больших Данных»
Сбор и работа с Большими Данными и их конвертация в денежную стоимость осуществляются в комплексных экосистемах, состоящих из множественных взаимосвязанных рынков, нередко многосторонних. В данном разделе дается краткое описание основных типов бизнеса и участников данных рынков.
а) Технология платформ
В центре экосистемы Больших Данных, где наблюдаются многие из вышеописанных проблем в области конкуренции, платформы выступают в качестве основного интерфейса между потребителями и участниками рынка. Выделим две основные категории: платформы привлечении внимания и платформы подбора19.
Платформы привлечения внимания (поисковики или социальные сети), как правило, предлагают набор «бесплатных» услуг, субсидируемых рекламой, продаваемой по принципу «за одно щелканье мышкой». Таким образом, вместо уплаты денег за услугу потребители платят своим вниманием к рекламе до получения доступа к содержанию запрошенного ими видео ролика.
Возможно, потребители также платят за данные либо косвенно (через регистрацию щелканий на веб-сайте при онлайновом поиске или покупках), либо непосредственно (вводя персональные данные в интерактивную анкету). Далее платформы для привлечения внимания клиентов используют частные данные пользователей для улучшения качества услуг и определения объектов рекламы, вследствие чего платформа привлекает новых потребителей и можно взимать повышенную «плату за щелканье» с рекламодателей.
Платформы подбора являются торговыми площадками, где разные виды участников могут взаимодействовать (покупатели и продавцы, работодатели и работники, или даже индивидуумы на сайтах Интернет-знакомств). Платформы подбора зарабатывают деньги, взимая фиксированную плату за доступ к платформе и меняющуюся плату за транзакцию. Нередко группа пользователей, характеризующаяся высокой эластичностью спроса, субсидируется другой группой (например, клиенты не платят за пользование сайтами для совершения покупок; соискатели работы не должны платить за использование сайтов занятости и т.д.). Сбор частных данных, однако, осуществляется у всех
групп, и затем применяется для повышения качества платформы и алгоритмов подбора, что, в конечном счете, ведет к повышению количества трансакций.
Многосторонние характеристики платформ имеют тенденцию к повышению в результате прямых и косвенных сетевых внешних эффектов, концентрации пользователей и соответствующих данных в руках нескольких игроков. В свою очередь, использование Больших Данных дает онлайновым платформам существенную рыночную власть в сфере поставок важных информационных услуг, на которые рассчитывают все компании и потребители. Действительно, такого рода бизнес-модели показали высокую прибыльность, и некоторые платформы привлечения внимания и платформы подбора смогли войти в 10 компаний с наилучшими показателями рыночной капитализации. Сама по себе высокая прибыльность не подразумевает вреда конкуренции, если только бизнес-успехи достигаются посредством инноваций на основе управления данными, а не использования Больших Данных для дискриминации некоторых участников рынка, навязывания издержек смены поставщика, эксклюзивных контрактов и других форм злоупотреблений.
б) Поставщики контента
Другая группа участников экосистемы Больших Данных — поставщики контента: журналы, сайты и разработчики приложений, создающие информативный контент, доступный на многих платформах, в обмен на позицию в списке результатов поиска. Создаваемый контент показывается не только поисковиками как элемент основного бизнеса, но и другими платформами (например, социальные сети, где требуется креативный контент для привлечения и удержания внимания потребителей и поддержания высокого уровня трафика). К сожалению, так как поставщики контента многочисленны, а платформ мало, информативный контент, реально доходящий до потребителей, может быть не только результатом конкурентных процессов, но и итогом стратегических решений платформ.
Поставщики контента делают деньги либо продавая продукт напрямую потребителям, либо продавая рекламное пространство продавцам. Однако поскольку они ощущают нехватку Больших Данных, необходимых для должного целевого рекламирования, все более распространенной практикой сайтов становится прогонка рекламных объявлений через платформу (например, Google) и получение доли рекламных доходов.
в) Продавцы
Основными спонсорами участников рынка являются продавцы или поставщики контента, предлагающие продукцию и услуги конечным потребителям в обмен на деньги. Сюда включены производители, оптовые продавцы, специалисты, агентства недвижимости, консультанты, финансовые институты и любые другие виды бизнеса, которые могут использовать маркетинговые каналы платформы, чтобы убеждать потребителей покупать их продукцию. Подавляющее большинство участников данной группы сталкивается с острой конкуренцией.
Ряд крупных продавцов, однако, способен достичь таких масштабов, чтобы использовать Большие Данные самостоятельно, как, например, Amazon, Tesco или Target (вторая в США крупнейшая сеть розничных магазинов со сниженными ценами). Собирая данные по Интернет-транзакциям, с карт лояльности и анкет, заполненных потребителями, иногда в обмен на ценовые скидки и бесплатные продукты, эти компании еще больше увеличиваются в размере, уходя в непреодолимый отрыв от более мелких конкурентов, не имеющих такого масштаба и дорогостоящей инфраструктуры для обработки Больших Данных, чтобы стать жизнеспособными конкурентами. Опять-таки
это не обязательно подразумевает нанесение вреда конкуренции, так как приращение эффективности и инновации, достигаемые крупными игроками, могут быть полезны для общества.
г) Инфраструктура, включая облачные вычисления и хранение данных
Провайдеры инфраструктуры информационных технологий (ИТ), как Hadoop, IBM и Oracle, оказывают ключевую поддержку операций, выполняемых пользователями Больших Данных. Компании, осуществляющие инновации на основе данных, быстро сталкиваются с петабайтами информации, хранить такой объем дорого и еще труднее обрабатывать, на что у компаний не хватает ресурсов. Провайдеры ИТ-инфраструктуры не только разрабатывают адекватное программное обеспечение для работы с Большими Данными, но самое важное — они предлагают возможности «облачных вычислений» и хранения, т.е. действуют как независимые центры данных, в которых компании хранят и обрабатывают данные по запросу. Как правило, такие центры — крупные кластеры компьютеров, соединенные скоростными локальными сетями, постоянно действующие и получающие значительные выгоды от экономики масштаба.
Появление облачных вычислений частично сняло проблему масштаба, связанную с ИТ-инфраструктурой, преобразуя постоянные издержки в переменные и давая малым фирмам возможность работать, не владея физическими инфраструктурными объектами. Когда такие компании, как Amazon, Google и Microsoft обеспечивают алгоритмы машинного обучения как элемент сервиса облачных вычислений, малым фирмам становится все удобнее обрабатывать и извлекать информацию из данных, используя внешнюю ИТ-инфраструктуру. По прогнозам Cisco, к 2019 г. 86% обработки коммерческих данных будет осуществляться путем облачных вычислений20. Но по мере расширения круга фирм, зависящих от инфраструктуры нескольких провайдеров, последние получают доступ к значительным объемам разнообразных данных, благодаря чему могут совершенствовать собственные алгоритмы анализа данных. Если тенденции не изменятся, в будущем может возникнуть проблема для конкуренции, поскольку новые участники рынка не смогут выстраивать достаточно мощную ПТ -инфраструктуру с аналитическим программным обеспечением, способным конкурировать с действующими игроками рынка.
д) Государственный сектор
Наконец, на противоположной стороне экосистемы находится государственный сектор, включающий центральное и местное правительства, а также государственные больницы, поликлиники, пенсионные фонды и другие государственные службы. Большие Данные собираются у граждан и иногда с платформ и от продавцов, когда последние по закону обязаны поставлять информацию. Государственный сектор является одним из наиболее информационно-емких секторов; в нем используются национальные базы данных для научных исследований и поддержки государственных услуг. Тем не менее можно развивать разработку имеющихся у правительственных организаций данных для общественных нужд, внедряя новые методы извлечения информации из данных и машинного обучения, созданные в частном секторе. В то же время использование Больших Данных для государственных услуг может вызвать проблему конкурентной нейтральности, поскольку в ряде областей частным фирмам трудно или даже невозможно конкурировать с государством, по крайней мере, без доступа к данным коллективного пользования.
Б. Потенциальные проблемы в области конкуренции, связанные с использованием Больших Данных
Поскольку получение и использование Больших Данных становится ключевым параметром конкуренции, компании будут все интенсивнее вырабатывать стратегии приобретения и поддержания преимущества в данных. Как доказывают Штюке и Эзрачи, «компании все больше применяют бизнес-модели, в которых персональные данные являются ведущим вводимым фактором производства... Компании предлагают индивидуумам бесплатные услуги с целью получения ценных персональных данных, которые помогут рекламодателям лучше делать целевую рекламу для воздействия на поведение»21. Хотя конкурентное соперничество и стимулы к поддержанию преимущества в данных могут быть проконкурентными, принося выгодные для потребителей и компании инновации, некоторые антимонопольные органы подчеркивают, что сетевые эффекты и экономика масштаба, вызываемые Большими Данными, могут также приводить к рыночной власти и долгосрочным конкурентным преимуществам22.
Вызывает ли использование Больших Данных проблему, отличную от использования обычных или традиционных данных? Местные магазины процветали благодаря знанию своих покупателей. Традиционный продавец всегда выстраивает тесные отношения с клиентами, чтобы знать их предпочтения и предложить продукцию согласно их требованиям. Равным образом производители используют прошлые данные для оценки спроса и совершенствования товаров в высококонкурентных отраслях. Исходя из этого, можно ли утверждать, что Большие Данные создают новую, ранее не наблюдавшуюся проблему для конкуренции?
В отличие от традиционного сектора розничной торговли современные бизнес-модели нередко характеризуются сетевыми эффектами на основе данных, благодаря которым можно улучшить качество продукции или услуг. Такие определяемые данными сетевые эффекты — это результат двух систем обратной связи с пользователями, показанных на рис. 1. С одной стороны, имея широкую базу пользователей, компания может собирать больше данных для совершенствования качества сервиса (например, создавая более качественные алгоритмы) и таким образом приобретать новых пользователей — «система обратной связи с пользователями». С другой стороны, компании могут изучать пользовательские данные для улучшения целевого рекламирования и монетизации услуг, получая дополнительные денежные средства для инвестирования в качество услуг и опять-таки привлечения больше пользователей — «система монетизации обратной связи». Такие бесконечные системы способны сильно затруднить конкуренцию любого нового участника рынка со «старожилами», имеющими широкую клиентскую базу.
Для иллюстрации — если поисковик получает только 1000 запросов в день, алгоритмы располагают меньшим объемом данных для изучения управляемых результатов поиска (отличных от более прямых запросов) и меньше связанных с ними поисков, которые можно было бы предложить пользователям. При низкокачественных результатах поиска маловероятно привлечение большого числа пользователей от более крупных систем поиска. При меньшем количестве пользователей поисковая система интересна меньшему количеству рекламодателей, что означает меньше возможностей пользователей перейти на платные результаты поиска и, соответственно, низкий доход от рекламы для расширения платформы на другие сервисы.
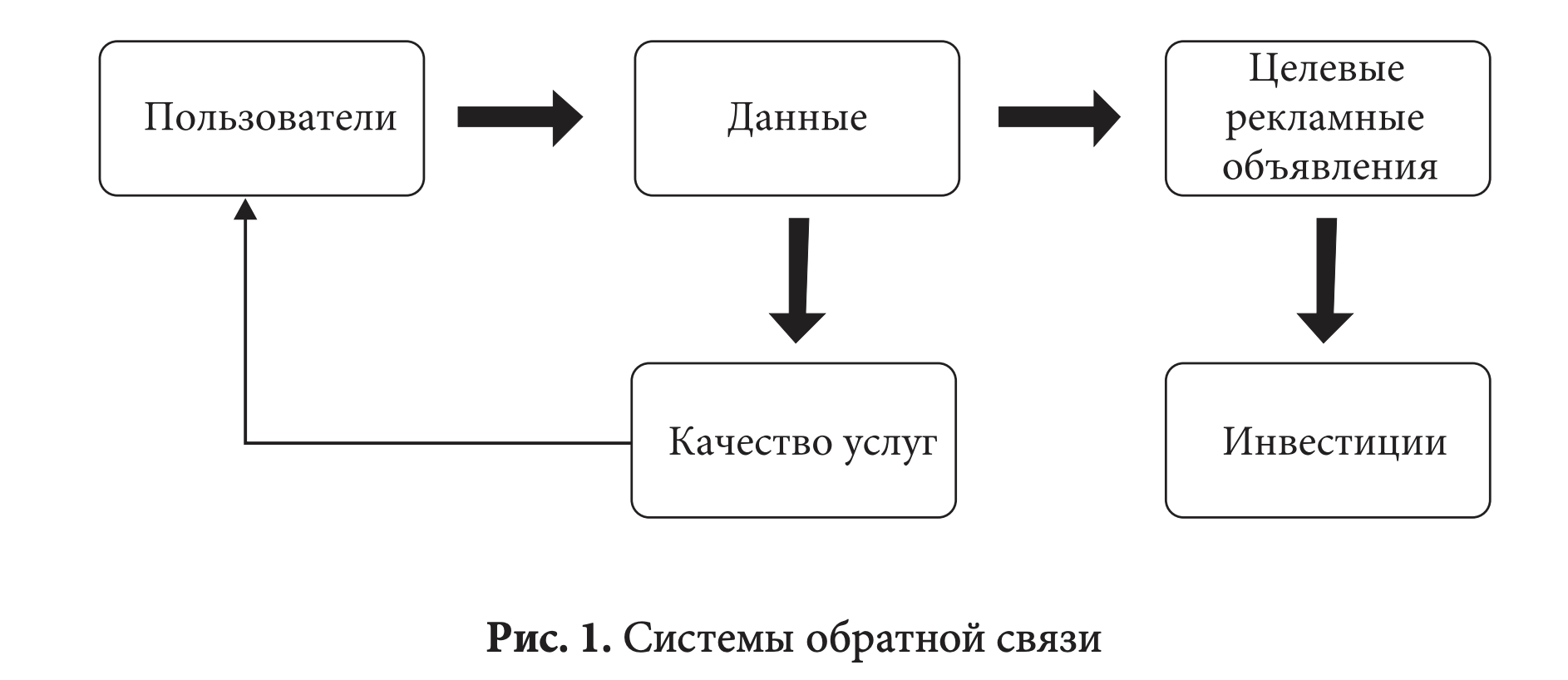
С приобретением каждого пользователя компанией по сравнению с конкурентами может возникнуть разрыв качества. Если пользователи замечают качественные различия, система обратной связи ускоряется, привлекая как новых пользователей, так и пользователей продукции конкурентов. На рынках с определяемыми данными сетевыми эффектами (поисковые системы, социальные сети и приложения управления с информацией, поставляемой сообществом) победитель не только получает потенциальный доход, например, когда пользователь щелкает на спонсируемых рекламных объявлениях; пользовательские данные также помогают повысить качество продукции, влияя на привлекательность продукта для будущих пользователей и рекламодателей. Подобные сетевые эффекты могут в конечном итоге сужаться. Однако сетевыми эффектами на основе данных на интерактивных рынках могут усилить процессы приобретения и потери пользователей.
В результате сетевых эффектов пользователи могут попасть в зависимость от доминирующей платформы, даже если они предпочитают другую платформенную модель. Например, хотя Интернет-пользователям могут импонировать предлагаемые некоторыми поисковыми системами опции сохранения конфиденциальности информации, крупные поисковики обеспечивают более целенаправленные результаты. Другой пример касается приложения пошаговой навигации, где меньшее приложение может обладать лучшими характеристиками, но пользователь нехотя применяет доминирующее приложение из-за лучшей информации о трафике, обеспечиваемой многими пользователям. Доминирующая платформа может не сделать ничего такого, чтобы быть признанной антиконкурентной, и все же система обратной связи может усиливать доминирование и препятствовать приобретению потребителей конкурентами.
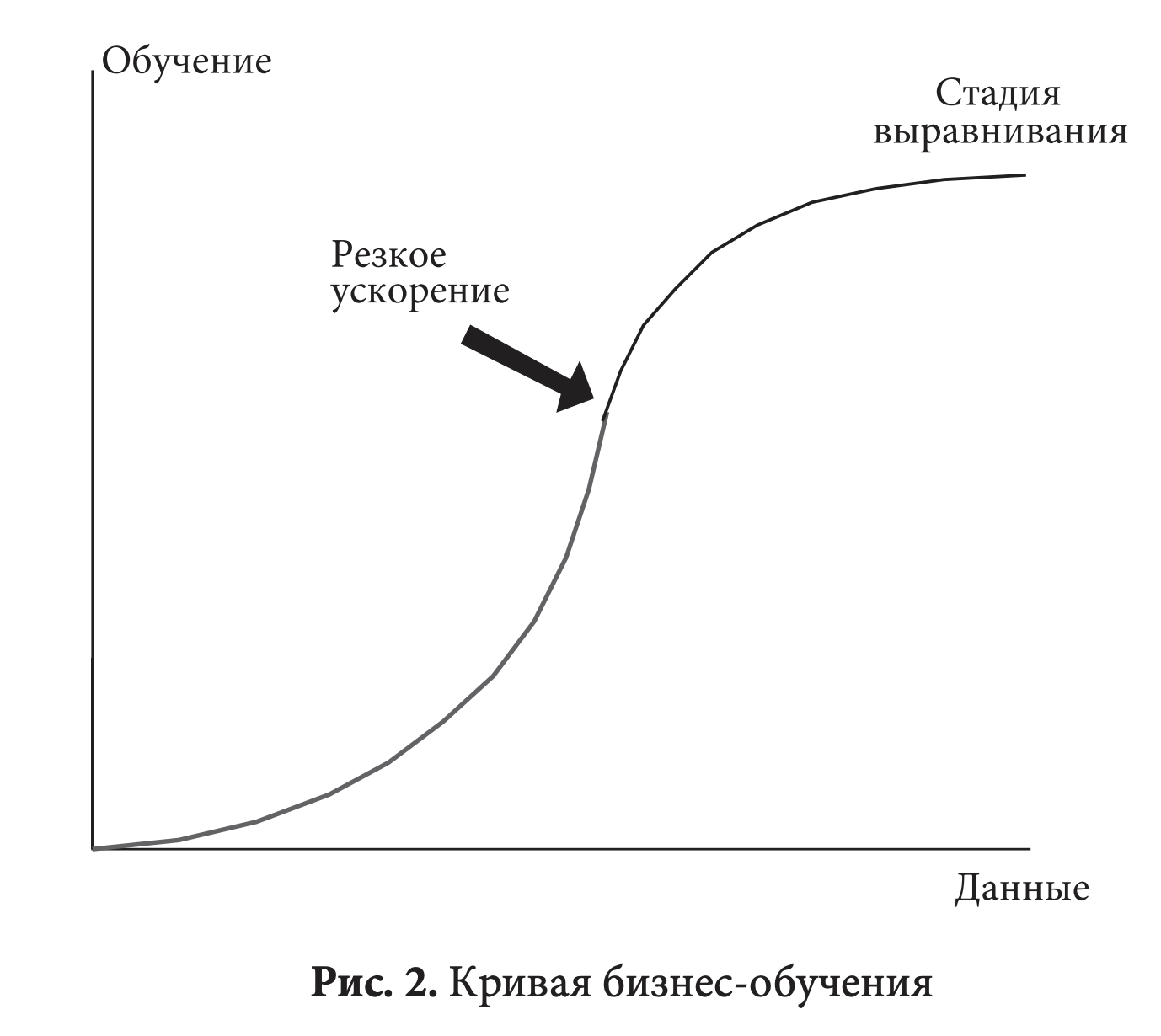
Другое различие между современными приложениями Больших Данных и традиционными бизнес-моделями касается недостаточной физической связи между количеством и разнообразием данных, которые можно собрать в цифровой среде, и неограниченным знанием, которое можно получить, запустив алгоритмы извлечения информации из данных по целому ряду массивов данных или используя синтез данных.
В результате Большие Данные сместили наклон кривой бизнес-обучения (Рис. 2), сделав участок резкого ускорения для присутствующей на рынке Больших Данных компании длиннее, а возрастающую доходность данных — менее истощаемой. Когда участник рынка Больших Данных, наконец, выходит на стадию выравнивания, он уже достиг столь больших размеров, что любому меньшему игроку будет трудно осуществлять конкурентное давление, создавая возможности «отклонения» рынка и результатов по принципу «победитель получает все».
Проблемы для конкуренции могут также возникать в связи с тем, что структура издержек обработки и использования информации довольно необычна, в их числе высокие начальные невозвратные издержки и стремящиеся к нулю предельные издержки23. Это особенно характерно для Больших Данных: информационные технологии хранения и обработки данных весьма затратны. Они охватывают крупные центры данных, серверы, программное обеспечение для анализа данных, Интернет-соединение с передовыми средствами сетевой защиты, высокооплачиваемые трудовые ресурсы (специалистов в области вычислительной техники и программистов). Как только система становится полностью работоспособной, данные в виде приращений могут «тренировать» и улучшать алгоритмы при низких издержках (также являясь, таким образом, элементом качества продукта или услуги). Такая структура издержек характеризуется значительным эффектом масштаба и диверсификации и может тем самым способствовать экономической концентрации, если на рынке Больших Данных действует небольшой круг участников.
Более того, в отличие от «малых данных», где единицы информации обеспечивают значимые и ценные представления, понятные человеку, ценность индивидуального наблюдения за Большими Данными невелика. К примеру, данные об одном щелканье мышкой на сайте бесполезны, если они не сопоставляются с миллиардом других подобных действий, которые затем нужно соотнести с решениями о покупках. Чтобы быть прибыльными, массивы Больших Данных нуждаются в масштабировании и чаще собираются именно крупными игроками. Наконец, другие конкурентные проблемы для конкуренции появляются из-за особенной структуры рынков, где, как правило, поддерживаются транзакции с Большими Данными.
Значение «больших данных» для контроля применения законодательства о конкуренции
В литературе нет консенсуса о влиянии Больших Данных на контроль реализации законодательства о конкуренции. Как представляется, растет понимание, что у антимонопольных органов есть четкая задача — предотвратить накопление рыночной власти через поглощения, например, когда защита конфиденциальности становится неотъемлемым качеством продукции. Другие исследователи, однако, утверждают, что действующие законодательные нормы по защите конфиденциальной информации и / или интересов потребителей адекватны для регулирования указанных проблем. В настоящем разделе рассматривается данная дискуссия и обсуждается потенциальное значение Больших Данных для эффективности инструментов конкуренции и основных направлений работы антимонопольных органов: анализ слияний, оценка злоупотреблений доминированием и борьба с картелями.
А. Действующие инструменты конкуренции, их ограничения и предлагаемые решения
Многие инструменты анализа конкуренции, например, определение рынка, недостаточны для полного учета характеристик цифрового рынка, скажем, при наличии бесплатных услуг. Тогда инструментарий типа критерия гипотетического монополиста или SSNIP-теста, равно как и большинство консенсуальных мер экономической концентрации, не охватывают специфические черты этих рынков.
Иногда простейшее внедрение текущих инструментов конкуренции оказывается достаточным; в других случаях регуляторы могут дополнительно ввести ряд критериев в рамках анализа конкретных дел. Мы постараемся не только выявить ограниченность нынешнего инструментария, но и предложить решения на основе свежего опыта.
1) Определение релевантного рынка для целей антимонопольного регулирования
В «экосистеме Больших Данных» эта задача особенно трудна, поскольку множество различных участников способны играть различные множественные роли и формировать между собой сложные отношения. На примере Apple видно, что такие компании одновременно являются платформой (через операционную систему iOS, Apple Store и iTunes), продавцами технологических продуктов (компьютеров, планшетов, телефонов, наблюдателей) и обеспечивают ИТ-инфраструктуру посредством сервиса iCloud. В то же время Apple взаимодействует со многими видами игроков, заключая сделки по продуктам и сервисам с потребителями, взимая плату с поставщиков контента (разработчиков приложения) за использование платформы Apple, продавая рекламное пространство и даже сотрудничая с другими платформами (в частности, Facebook или LinkedIn).
Из-за многосторонней структуры платформы антимонопольным органам, возможно, придется модифицировать традиционные SSNIP-тест и критерий гипотетического монополиста (Вставка 2). Хотя теория экономики многосторонних платформ не нова, выявить многосторонность рынка, где цифровые платформы участвуют в обмене данных, может оказаться весьма трудной задачей. К примеру, традиционная платформа, газеты, четко действуют одновременно на рынке новостей и рекламы, меняя цену как для читателей, так и для рекламодателей. Но гораздо менее очевидно, на каком рынке работают компании типа Google, обеспечивающие многочисленные бесплатные сервисы (поиск, перевод, GPS-навигация, загрузка видео роликов и социальная сеть помимо всего прочего). Чтобы знать многосторонний рынок, недостаточно рассматривать денежные операции, одинаково важно изучать любые потоки данных, которые наблюдаются на рынке.
То, что сбор данных для коммерческих целей позволяет компаниям предлагать все более широкий спектр продуктов бесплатно, имеет последствия для определения размеров релевантных рынков, поскольку SSNIP-тест и тест гипотетического монополиста принципиально опираются на ценовые механизмы. В результате, если продукты и услуги бесплатны, одним из нескольких возможных решений для определения рынка может быть количественная оценка качества, например, использование SSNDQ-теста для измерения последствий («небольшое, но существенное и долговременное уменьшение качества»)24. Хотя данный критерий иногда применяется в отраслях, где качественные показатели являются общепринятыми и количественно измеримыми (например, здравоохранение), он также эпизодически используется в других отраслях, где адекватные показатели измерения качества еще предстоит разработать.
Определение рынка для многосторонних платформ
Цифровые рынки нередко характеризуются многосторонними параметрами и перекрестными внешними эффектами, что значительно усложняет определение рынка. Проблема изучена рядом авторов, начиная с классической работы Роше и Тирола25 о конкуренции на многосторонних рынках. Позже Эванс и Ноэль26, а также Филистручи и др. сформулировали полезные выводы о адаптации традиционных инструментов определения рынка для платформ привлечения внимания и платформ подбора. В частности, предложен модифицированный SSNIP-тест, в котором учитываются перекрестные внешние эффекты роста цены на различные стороны рынка. Что касается платформ привлечения внимания, в литературе сложился консенсус, что если только потребители, рекламодатели, поставщики контента и другие участники не осуществляют прямых трансакций друг с другом, регуляторам следует давать разные определения рынка для каждой стороны платформы27. Базовое обоснование определения множественных рынков заключается в том, что продукты могут восприниматься с разной степенью взаимозаменяемости на разных сторонах платформы: например, социальные сети и поисковые системы могут рассматриваться в качестве взаимозаменяемых для рекламодателей, но не для потребителей. Кроме того, как предполагают Эванс и Ноэль28, Филиструччи и др.29, при определении каждого рынка необходимо учитывать все внешние эффекты для остальных сторон. С этой целью антимонопольные органы могут применять модифицированный SSNIP-тест, оценивающий воздействие повышения цены на одном рынке на общую прибыльность платформы, включив в анализ перекрестную эластичность спроса между множественными сторонами. Определение рынка является менее сложным для платформ подбора, и большинство авторов согласно, что, как правило, достаточно определить один рынок, так как все транзакции происходят одновременно на разных сторонах платформы. В таком случае Filistruchi и др.30 рекомендуют антимонопольным органам применять единый модифицированный SSNIP-тест, измеряя общую прибыльность небольшого повышения итоговой цены, устанавливаемой платформой. Фундаментальная разница при таком подходе состоит в том, что изменение цены может включать одновременные изменения постоянных и переменных сборов за транзакцию, взимаемых со всех сторон платформы. Тем не менее, ряд вопросов остается не рассмотренным исследователями. Что происходит, например, когда одна сторона платформы получает выгоды, а другой стороне (потребителям) наносится ущерб? Постарается ли антимонопольный орган суммировать и вычитать эффекты? Должен ли антимонопольный орган придавать больше значения интересам потребителей или нет? Последнее трудно, если одна сторона субсидирует другую. Более того, поскольку дело касается данных, будет ли антимонопольный орган также рассматривать эффекты, слияние которых на основе данных может помочь фирме приобрести или удержать власть на других рынках, связанных с платформой? Простых ответов на данные вопросы нет, и правоприменительная практика еще не накоплена. При слиянии на базе данных, например, возникающая в результате слияния эффективность может снижать рекламные издержки и нести выгоды рекламодателям благодаря улучшению целевой рекламы, влияющей на поведение потребителей, тогда как потребители по-прежнему будут получать бесплатные сервисы от другой стороны платформы. В свете данной дискуссии это будет положительным фактором. Предположим, однако, что качество в форме защиты конфиденциальных данных ухудшится после слияния. Тогда потребителям будет нанесен вред, поскольку защита конфиденциальности уменьшится в небольшой, но существенной постоянной степени. Что будет делать в этом случае антимонопольный орган для поддержания баланса между выгодами рекламодателя и потерями потребителя? Именно такого рода вопросы в ближайшем будущем выйдут на передний план для рынков, ориентированных на данные.
2) Оценка рыночной власти
Рыночную власть особенно трудно оценить, когда фирмы предлагают потребителям бесплатные сервисы в обмен на данные. Регуляторы могут недооценить степень рыночной власти или даже предположить, что на данном рынке конкурентных проблем нет. Однако бесплатное предложение может быть элементом стратегии максимизации прибыли для привлечения чувствительных к цене потребителей и затем обретения рыночной власти над другими группами участников, например, продавая информацию на других сторонах рынка (т.е. к примеру, на некоторых типах платформ Интернет-знакомств, когда доступ женщин бесплатный, а мужчин — платный). Рыночная власть также может быть реализована посредством неценовых аспектов конкуренции (фирмы предлагают продукцию или услуги ухудшенного качества, навязывают большие объемы рекламы или даже собирать, анализируют или продают избыточные данные о потребителях).
Антимонопольные органы Франции и ФРГ31 отмечают, что даже при бесплатной продукции обладание Большими Данными может стать важным источником рыночной власти, особенно когда такие данные могут использоваться как барьеры. Именно такое соображение послужило обоснованием блокировки Министерством юстиции США сделки слияния Bazaarvoice и Power-Review. Если бы сделка была разрешена, могли бы возникнуть серьезные барьеры входа на рынок для «платформ рейтинга и анализа» из- за потенциальной монополизации данных. Это и другие дела показывают, что на рынках с бесплатными предложениями рыночную власть лучше измерять долей контроля над данными, а не долей продаж или с помощью других традиционных методов.
Наконец, исходя из особенностей цифровой экономики, часто фирмы конкурируют за рынок вместо того, чтобы конкурировать на рынке, что ведет к ситуации «победитель получает все» (что произошло, когда Facebook вытеснила Myspace в качестве наиболее популярной социальной сети). Такая форма конкуренции типична среди цифровых платформ, и могут потребоваться новые критерии должной оценки рыночной власти (см. Вставку 3). В таких случаях упор на состязательности рынков играет решающую роль для гарантии, что доминирующие компании по-прежнему будут ощущать конкурентное давление, постоянно стимулирующее совершенствование продукции и сохранение низких цен.
Оценка рыночной власти платформ
Антимонопольный орган ФРГ опубликовал отчет (2016) с рекомендациями по улучшению оценки рыночной власти в особой ситуации платформ и сетей. Признавая наличие высокой отдачи от масштаба, связанного с Большими Данными, равно как и прямые и косвенные сетевые эффекты, которые могут приводить к монополизации рынков, орган предлагает рассматривать дополнительные критерии при оценке состязательности рынков. Согласно отчету, рыночная власть может ограничиваться способностью потребителей работать с несколькими физическими линиями данных и, что важнее, стимулами так поступать. Например, на рынке поисковиков практически нет ограничений для работы с несколькими физическими линиями данных, но пользователей- поисковиков можно поощрять систематически использовать одну и ту же поисковую систему с помощью выбора по умолчанию или сетевых эффектов, изменить которые трудно. Инертность потребителей также означает предрасположенность к выбору по умолчанию на используемом устройстве. Новым участникам рынка это усложняет набор критической массы осуществляющих поиск пользователей, необходимой для утверждения своих позиций. Другие критерии, предложенные антимонопольным органом ФРГ, касаются выяснения: достаточно ли платформы дифференцированы, благодаря чему можно ориентироваться на разные группы потребителей, и уменьшается риск монополизации. Другой момент заключается в том, что любые технологические или физические ограничения платформ, которые приводят к перегрузке, повышают стимулы входа. Наконец, если рынок обладает высоким инновационным потенциалом, это ограничивает возможности монополизации, так как интенсифицируется динамическая конкуренция и новые участники могут опередить действующих участников рынка.
Б. Основные направления деятельности антимонопольных органов: противодействие картелям, оценка злоупотребления доминирующим положением и анализ сделок слияния
- Сговоры
В современной литературе практически отсутствует дискуссия о последствиях Больших Данных для выявления и расследования картелей, возможно, из-за того, что пока расследовано очень мало подобных дел. Тем не менее воздействие Больших Данных на благополучие потребителей станет значительным по мере того, как передовые методы анализа данных, средства программирования и искусственный интеллект повышают прозрачность и возможности сопоставления цен через Интернет, что скорее всего будет способствовать значительному усилению координации на рынке.
а) Появление цифровых картелей
Есть доказательства, что цифровые картели появились прежде чем Большие Данные стали «большими». В известном деле, расследованном Министерством юстиции США в 1990-х гг., ведущие американские авиакомпании обвинялись в использовании базы данных с подробной информацией о ценах на билеты для повторяющихся объявлений тарифов и быстрого изменения цен, чтобы вступить в онлайновый сговор (Вставка 4). Но через три года дело было закрыто ввиду заключения мирового соглашения между Министерством и авиакомпаниями; таким образом, судебного прецедента не возникло.
В 2015 г. Министерство юстиции США впервые привлекло к суду действовавший на цифровом рынке картель, участниками которого были несколько продавцов, устанавливавших цены на рекламные объявления, продававшиеся на электронной торговой площадке Amazon. В частности, Министерство предъявило обвинение должностному лицу компании, разработавшему ценовый алгоритм, реагирующий на предпочтения потребителей, который был предоставлен другим продавцам и реализован параллельно в целях координации цены. Заместитель генерального прокурора США Б.Байер тогда заявил: «Мы не потерпим антиконкурентного поведения, имеет ли оно место в курилке или в Интернете с использованием сложных ценовых алгоритмов»32.
Поскольку антимонопольные органы по-прежнему редко уделяют внимание цифровым картелям, компании имеют огромные стимулы для поиска новых «креативных» способов использования Больших Данных с целью сговора, особенно если усовершенствованные антиконкурентные практики сложно выявить и доказать в суде. Штюке и Эзрачи33 описывают четыре потенциальные стратегии использования Больших Данных в целях сговоров, и антимонопольным органам полезно изучить данную информацию.
Во-первых, фирмы могут использовать анализ данных в режиме реального времени для мониторинга соответствия прямо сформулированному соглашению, во всех остальных аспектах схожего с традиционным картелем. Во-вторых, фирмы могут коллективно использовать идентичные ценовые алгоритмы, позволяющие им одновременно корректировать цены на основе поступающих данных о рынке, как, например, в деле об установлении цены на рекламные объявления. Если конкуренты используют вертикально-интегрированную компанию для реализации алгоритма, может возникнуть классический разветвленный картель. В-третьих, на высокоорганизованном уровне фирмы могут использовать Большие Данные для скрытого сговора либо повышая прозрачность рынка, либо путем более взаимозависимых действий — например, программируя немедленные ответные меры при снижении цены. В-четвертых, компании могут использовать искусственный интеллект для создания максимизирующих прибыль алгоритмов, которые через машинное обучение ведут к скрытому сговору, даже если изначально программист не предвидел такого результата.
Две последние стратегии становятся серьезной проблемой для антимонопольных органов — доказать намерение координации цен очень трудно или невозможно с помощью нынешних инструментов антимонопольного контроля. В частности, в случае с искусственным интеллектом нет юридических оснований привлекать к ответственности специалиста по вычислительной технике за программирование вычислительной машины таким образом, что в конце концов она «самообучилась» координировать цены с другими машинами34.
Дело авиакомпаний в США
В 1990-х гг. Минюст США расследовал установление тарифов авиаперевозок. Участники картеля скрытно координировали тарифы, используя центр сторонней компании и тщательно разработанные сигнальные механизмы. Дело подробно описано С.Боренштейном35. Авиакомпании в США ежедневно отправляли информацию о ценах на билеты в Компанию по публикации тарифов авиакомпаний (АТРСО). Это центральная информационная служба, которая собирает все поступающие данные и передает их в режиме реального времени турагентам, системам компьютерного бронирования билетов, потребителями и даже непосредственно авиакомпаниям. База данных АТРСО, включает, помимо всего прочего, информацию о ценах, датах поездки, аэропортах вылета и прилета, ограничениях по билетам, так же как начальную и конечную даты на билетах, обозначающие временной интервал, в течение которого билеты поступают в продажу по указанной цене. По данным Министерства юстиции, авиакомпании использовали начальные даты билетов для объявления о повышении тарифов за несколько месяцев вперед. Если бы конкуренты действовали соответственно этим заявлениям, то при наступлении начальной даты все компании повышали бы тарифы одновременно. Некоторые координационные стратегии были более изощренными, включая использование кодовых номеров тарифов и примечания к дате билета для подачи сигналов или переговоров о мультирыночной координации. Министерство юстиции доказывало, что именно механизм быстрого обмена данными для мониторинга тарифов и оперативного реагирования на изменения цен позволил компаниям достичь сговора при отсутствии коммуникации в явной форме. Поскольку законодательство о конкуренции не запрещает скрытых сговоров, а неявные согласованные действия при рассмотрении уголовного дела доказать очень трудно, в конечном итоге Министерство пошло на мировое соглашение36 с авиакомпаниями: последние согласились в основном прекратить заранее объявлять о повышении цен, за исключением ряда обстоятельств, когда раннее оповещение может способствовать повышению благосостояния потребителей. Все тарифы авиакомпаний-ответчиков должны были стать параллельно доступны для продажи потребителям.
б) Антимонопольное регулирование в области Больших Данных
Остается неясным, как антимонопольные органы скорректируют инструментарий противодействия цифровым картелям, но, вероятно, любой действенный ответ потребует использования аппарата теории игр и действия аналогичным образом. Другими словами, для выявления согласованных действий на цифровом рынке, возможно, придется внедрять усложненные методы анализа данных в правоприменительную практику по делам о нарушении норм конкуренции. Для этой цели антимонопольным органам могут потребоваться дополнительные ресурсы, например, специалисты по компьютерным технологиям.
В экономической литературе предлагаются методы разграничения состояния конкуренции и сговора на основе результатов наблюдений, обычно известные как методы скрининга, хотя они еще не стали распространенными37. Харрингтон38 рассматривает эмпирические подходы к выявлению картелей, включая модели обнаружения подделок заявок в ходе государственных закупок39 и модели проверки ценовых сговоров40. Постоянно развиваются новые методы, например, концептуальная схема, разработанная Мармером и др.41 для выявления сговоров на открытых аукционах с восходящими ценами, все чаще наблюдаемых на Интернет-рынке. Преимущество методов скрининга на базе анализа данных состоит в быстром выявлении как формализованных, так и неформализованных картелей, что означает возможности выявления всех форм картелей, действующих в Сети. Когда фирмы используют алгоритмы и машинное обучение для скрытых сговоров, методов скрининга недостаточно, поскольку фирмы можно осудить только если они участвуют в явно выраженном процессе коммуникации в любой форме или, по крайней мере, показывают намерение участвовать в сговоре. Определение способов предотвращения сговоров между самообучающимися алгоритмами, возможно, является одной из самых сложных проблем, с которой когда-либо сталкивались антимонопольные регуляторы, и решение которой может включать искусственное формирование более неустойчивых рыночных условий и меньшей предрасположенности к скрытым сговорам. Штюке и Эзрачи42 предлагают пути достижения данной цели — спонсирование входа независимой компании, чей быстрый рост может разрушить картель; создание системы секретных скидок, посредством которых фирмы могут снизить цены незаметно для соперников; применять минимальный промежуток времени для изменений цены, чтобы стимулировать компании предлагать более низкие цены, чем установленные. Но, как они напоминают, у каждого решения есть недостатки. Таким образом, предлагаемые ими решения пока находятся на ранней стадии разработки и необходимы дальнейшие исследования в данной области.
- Злоупотребление доминированием
Управление большим объемом разнообразных данных может быть важным источником роста производительности и создании инновационной продукции. Когда Большие Данные сконцентрированы в руках небольшого количества крупных участников рынка, такие игроки приобретают существенное преимущество, с которым трудно конкурировать новым участникам рынка. Хотя сбор и управление существенными объемами данных законны, ненадлежащее использование Больших Данных в целях повышения издержек входа или поддержания рыночной власти может быть признано нарушением законодательства о конкуренции, требующим вмешательства антимонопольных органов.
а) Исключающее поведение
Цель исключающего и хищнического поведения, обусловленного контролем данных, может состоять в ограничении возможности своевременного доступа конкурентов к ключевым данным, препятствовании коллективному использованию их другими участниками рынка или переносимости данных либо вытеснению соперников, несущих угрозу связанному с данным конкурентным преимуществом действующего участника рынка. Эти цели достигаются, например, через эксклюзивные контракты со сторонними поставщиками данных.
В совместном отчете антимонопольных органов43 выделены формы злоупотреблений, включая использование Больших Данных для закрытия рынка. Один из приведенных там примеров касается дискриминационного доступа к данным с намерением обеспечить необоснованное преимущество компании над конкурентами. Это наблюдается, например, когда поставщик, платформа или оператор торговой площадки вертикально интегрирован в розничный рынок и использует доступ к данным в сегменте поставщиков для получения несправедливого преимущества над другими розничными продавцами. Даже при отсутствии вертикальных взаимоотношений компания может дискриминировать доступ к данным, чтобы остановить сильного конкурента. Антимонопольная служба Франции (ADLC) расследовала действия компании Cegedim44: отказ продавать информацию из медицинской базы данных (над которой компания имела эксклюзивный контроль) любым потребителям, пользующихся программным обеспечением кого-либо из основных конкурентов компании.
Антимонопольная служба Великобритании (СМА)45 отмечает, что фирмы могут использовать контроль данных на рынках для усиления своей власти на других взаимосвязанных рынках, применяя связывающие или навязывающие стратегии. Фирмы могут навязывать покупку их массивов данных совместно с их сервисами анализа данных. Иногда связывающие продажи порождают выгоды эффективности. Однако каждый случай нужно рассматривать отдельно, чтобы выяснить, кроме всего прочего, не является ли целью непосредственно монополизация данных и повышение издержек или же препятствие входу новых конкурентов на рынок.
Менее очевидный вид исключающего поведения может принимать форму нарушения прав потребителей на защиту конфиденциальности информации — к такому выводу пришел антимонопольный орган Германии в ходе расследования Facebook. Президент Bundeskartellamt А. Мундт заявил: «Важно понять в контексте злоупотребления рыночной властью, были ли потребители информированы о виде и объеме собираемых данных»46.
Следует ли анализировать нарушения конфиденциальности в рамках законодательства о конкуренции, или этим должны заниматься органы защиты прав потребителей — по-прежнему вопрос открытый, и ответ на него зависит от природы злоупотребления. Например, антимонопольные органы должны обратить внимание, если можно обоснованно считать, что нарушение конфиденциальности способствует приобретению или поддержанию монопольной власти (особенно на рынках с сильными сетевыми эффектами, обусловленными контролем над данными). Или когда нарушение конфиденциальности является исключающим поведением — извлечение конфиденциальной информации, недоступной конкурентам и использование этих данных для исключения соперников или наращивания барьеров входа на рынок.
б) Данные как важнейшие исходные ресурсы и доктрина ключевых мощностей
Специалисты-практики обсуждают, можно ли рассматривать данные в качестве важнейших исходных ресурсов на ряде рынков, без которых компании не могут конкурировать. Ясно, что в некоторых случаях данные, а точнее, знание, полученное из данных, является источником существенного конкурентного преимущества47. Соответственно дискутируется, уместно ли использовать аргумент «ключевых мощностей».
Признавая, что доктрина ключевых мощностей не является общепризнанной в практике судебных или антимонопольных органов, добавление быстро меняющихся и спекулятивных требований о применении этой доктрины является особенно сложным и сталкивается с серьезным сопротивлением не только в исследованиях, спонсированных участниками рынка48, но и со стороны некоторых практиков в области антимонопольного регулирования (Балто и Лейн)49 и ученых (Сокол и Комерфорд)50. Указанные авторы, как правило, утверждают, что данные не составляют решающего ресурса успеха любой фирмы, поскольку новые инновационные участники способны утвердиться на рынке, несмотря на изначально небольшую долю пользовательских данных: «...в истории цифровой экономики есть много примеров: Slack, Facebook, Snapchat и Tinder, когда понимание потребностей клиентов позволило выйти на рынок и стремительно преуспеть вопреки сетевым эффектам»51.
Действительно, указанные новые участники рынка сумели оттеснить действующих игроков с их позиций, но роль Больших Данных в качестве важнейшего элемента бизнес-стратегии — относительно новое явление, и технологические разработки и бизнес-модели, вытекающие из использования технологий глубокого обучения, значительно отличаются от того периода, когда компании выходили на рынок. Поэтому вполне возможно, что новым компаниям становится все труднее разработать инновационные решения, которые являются прорывными для оказания конкурентного давления на доминирующих игроков рынка или участников с прочными позициями.
Для применения так называемой доктрины ключевых мощностей недостаточно показать, что Большие Данные являются незаменимым исходным ресурсом; необходимо также доказать, что конкуренты не в состоянии их дублировать52. Оппоненты доктрины ключевых мощностей нередко прибегают к доводу, что данные нельзя легко монополизировать: они не имеют конкурентного характера и, как утверждают, неэксклюзивны, так как нет соглашений, препятствующих пользователям делиться своими персональными данными со многими компаниями. Более того, аргументируется, что существует очень мало барьеров на пути доступа новых платформ на рынок, поскольку сбор данных относительно недорог, данные имеются в большом количестве и действительны в течение короткого периода времени53. Однако, как было сказано ранее, не столько сбор данных, сколько способность оперативно извлекать полезную информацию из большого объема разнообразных данных обеспечивает конкурентное преимущество.
- Анализ сделок слияния
Анализ Больших Данных в рамках конкурентной политики обосновывается, по крайней мере, частично, рядом трансграничных сделок, например, слияний Google/ DoubleClick54 и Facebook/WhatsApp55, привлекших внимание общественности и специалистов-практиков. Эти сделки не соответствуют традиционной категоризации, поскольку их трудно квалифицировать как горизонтальные или конгломератные слияния, и антимонопольным органами пришлось бы проводить сложный анализ.
Когда антимонопольные органы сосредотачиваются исключительно на ценовых эффектах сделки, некоторые слияния могут получить безусловное одобрение, неся между тем потребителю в дальнейшем значительные издержки. Однако если учитывать риск монополизации данных или издержки нарушения конфиденциальности потребителей, решения могут радикально измениться, отразив другие важные аспекты конкурентной политики. В данном разделе обсуждается, каким образом вопросы сохранения конфиденциальности влияют на анализ сделок слияния, и достаточны ли существующие пороговые значения нотификации для выявления сделок, обусловленных Большими Данными.
а) Учет аспектов соблюдения конфиденциальности данных при анализе сделок слияния Накопление большого объема данных о поведении потребителей и распространение целевой рекламы накладывает на потребителей издержки в форме потери конфиденциальности. Плата, фактически выплачиваемая потребителями за Интернет-услуги, значительно выходит за рамки регулярных рекламных пауз (например, при использовании сервиса потоковой передачи музыки, Spotify) или баннерной рекламы рядом с вводом поискового запроса. Данные о потребителях и запросах поиска также анализируются программным обеспечением интеллектуального анализа данных, что иногда означает значительное вмешательство в частную жизнь. Примером служит анекдотический случай с Target, второй в США сетью розничных магазинов со сниженными ценами. Target использовал данные о предшествующих покупках, в частности, для оценки в баллах вероятности беременности у покупательниц. Согласно пресс-релизу56, эта компания на основании собственных вероятностных расчетов послала множество купонов на детские изделия девочке-подростку, что в конце концов насторожило ее отца, который решил, что дочь беременна.
Этот и подобные случаи способствовали росту озабоченности защитой конфиденциальности потребительской информации в контексте использования Больших Данных. Беспокойство проявляют не только организации, защищающие интересы потребителей и конфиденциальность данных, но и антимонопольные органы, которые уже начали включать компоненты защиты конфиденциальности в конкурентную политику. По-видимому, первое дело о нарушении антимонопольных норм, касающееся конфиденциальности информации, связано со слиянием Google/DoubleClick; член Федеральной торговой комиссии США П. Харбор поставила тогда вопрос о том, что слияние лишит потребителей «значимых возможностей конфиденциальности данных» (тем не менее Комиссия одобрила сделку)57. А когда было объявлено о создании совместного предприятия Microsoft и Yahoo, председатель подкомитета Сената по антитрасту X. Коль напомнил о важности оценки воздействия сделки на конфиденциальность данных Интернет-пользователей58.
Введение защиты конфиденциальности в конкурентную политику не является всеобщей практикой. Некоторые деятели конкурентного сообщества полагают, что единственной целью конкурентной политики должно быть содействие конкуренции как средства эффективного распределения ресурсов, тогда как другие общественные интересы должны защищаться иными государственными органами59. Например, Купер60 доказывает, что защита конфиденциальности в рамках законодательства о конкуренции приведет к нежелательной субъективности в антимонопольном правоприменении и может вступать в конфликт с фундаментальным правом на свободу слова, защищаемым Первой поправкой в США и конституциями многих других стран.
С другой стороны, аргументируется, что в условиях, когда нарушение конфиденциальности компаниями имеет место при осуществлении рыночной власти, у антимонопольных органов могут быть законные основания рассматривать вопросы конфиденциальности как проблему антимонопольного регулирования61. Поскольку данные характеризуются как «новая валюта Интернета», рост сбора частных данных можно сопоставить с ростом цен. Или равным образом, если потребители ценят конфиденциальность, снижение ее уровня аналогично снижению качества сервиса. Например, в деле Facebook/WhatsApp62 (Вставка 5) сотрудники Европейской комиссии отметили, что если после реализации сделки веб-сайт «начнет требовать от потребителей сообщать больше персональных данных или давать такие данные третьим сторонам на условиях доставки своей «бесплатной» продукции, это можно будет рассматривать либо как повышение цены, либо снижение качества продукции»63.
В целом антимонопольные органы признают важность качества как конкурентной характеристики, особенно когда продукт или услуга предлагаются «бесплатно»64. Вопросы соблюдения конфиденциальности могут попадать в сферу неценовой конкуренции. Киммель и Кестенбаум утверждают65: «Антимонопольное регулирование касается потребительского выбора, а цена — только один из видов выбора. Конечной целью антимонопольного законодательства является способствовать тому, чтобы свободный рынок принес потребителям все, что они хотят от конкуренции. Естественно, сначала идет конкурентная цена, но потребители также хотят оптимального уровня разнообразия, инноваций, качества и других форм неценовой конкуренции, включая защиту конфиденциальности».
Сбор персональных данных не обязательно ухудшает положение потребителей, поскольку позволяет компаниям улучшать качество продукции и грамотнее делить потребителей на группы. Тем не менее конфиденциальность, несомненно, является аспектом качества, который можно охарактеризовать как форму горизонтальной дифференциации, так как одни потребители предпочитают высокую степень защиты данных, а другие — стремятся раскрывать данные о себе, чтобы получать выгоды от более персонализированных и целевых реклам66.
Рассмотрение конфиденциальности как параметра неценовой конкуренции будет иметь существенное значение для анализа сделок слияний и в итоге влиять на решения о разрешении или блокировке сделки. В частности, оценивая, может ли слияние существенно ухудшить благосостояние потребителей, имеющих строгие предпочтения, антимонопольные органы смогут отказывать в одобрении поглощения фирм, предлагающих услуги с усиленной защитой конфиденциальности. Такова ситуация с Интернет-компанией DuckDuckGo, предлагающей услуги поисковой системы без сбора или обмена какой-либо персональной информацией (например, IP-адреса, запросов поиска и прошлых запросов). У фирмы есть дополнительные механизмы защиты данных, не допускающие любых видов cookie-файлов, сохраняемых в клиентской системе в браузере, и направляющие пользователей на кодированные версии основных сайтов, а также обладающие опцией отключения рекламы).
Слияние Facebook/WhatsApp
Социальные сети и передача текстовых сообщений — одни из наиболее популярных сервисов на Интернет-рынке, особенно широко использующиеся молодежью. Согласно некоторым исследованиям67, в 2015 г. американские подростки посылали и получали в среднем по 30 текстовых сообщений в день, 71% пользовались услугами Facebook. Поскольку WhatsApp владела ведущей платформой обмена сообщениями, a Facebook предлагала наиболее широко используемую социальную сеть и собственные платформы обмена сообщениями, фотографиями и видео (например, Facebook Messenger и Instagram), слияние двух компаний оказалось в центре дискуссий о Больших Данных, конкуренции и конфиденциальности. Дело Facebook/WhatsApp иллюстрирует типичное слияние двух горизонтально дифференцированных продуктов, обеспечивающих различные соотношения цены и конфиденциальности. Сервис WhatsApp всегда был либо бесплатным, либо в некоторых странах с пользователей взималась номинальная плата в обмен на сервис без рекламы и без сбора персональных данных, а услуги обмена сообщениями в Facebook всегда были бесплатными, но включали сбор данных для целевой рекламы. В заявлении Центра сохранения конфиденциальности информации, передаваемой электронными средствами68, подчеркивается, что Служба сообщений Facebook общеизвестна практикой обширного сбора данных. Когда Facebook модернизировала систему обмена текстовыми сообщениями в ноябре 2010 г., все пользователи системы были автоматически подписаны на нее и изначально блокирована возможность удалять отдельные сообщения. Без согласия пользователей новая система передачи сообщений также собирала данные из профиля в социальной сети Facebook для определения приоритета сообщений определенных пользователей. Сейчас даже если пользователь удаляет сообщение, оно продолжает храниться на серверах. В конце 2013 г. Slate69 сообщил, что даже когда пользователь решает не отправлять сообщение, Facebook по- прежнему отслеживает, что пользователь написал».
Несмотря на опасность нарушения конфиденциальности, Федеральная торговая комиссия и Европейская Комиссия одобрили слияние70 на условиях, что сервис WhatsApp продолжит соблюдать предшествующую политику конфиденциальности и получать согласие пользователей перед изменением любых процедур. Анализ сделки показал, что высокая концентрация данных по-прежнему не приведет к доминированию на рекламном рынке образовавшегося в результате слияния хозяйствующего субъекта, учитывая присутствие конкурентов, контролирующих значительную долю сбора данных в Сети. Однако Штюке и Грюнс71 предполагают, что при анализе не принято во внимание возможное в будущем воздействие ухудшения качества на потребителей, которые могут не осознавать любые последующие изменения в процедурах конфиденциальности или не иметь стимулов к переходу на другие системы обмена сообщениями с лучшей защитой конфиденциальности из-за замыкания на данном сервисе в результате сетевых эффектов. И действительно, 25.08.2016 WhatsApp объявила о скором переходе к «обмену некоторой информацией о подписчиках с Facebook»72.
б) Пороговые значения нотификации в сделках слияния, касающихся Больших Данных
Во многих странах введены пороговые значения нотификации для выявления слияний, подлежащих уведомлению в антимонопольные органы. В большинстве случаев такие пороговые значения основаны на обороте компаний-участников сделки73. Иногда, однако, пороговые значения по обороту не выявляют поглощений, имеющих важное последующее воздействие на конкуренцию (например, когда действующий участник рынка, стимулируемый перспективой доступа к разнообразным дополнительным источникам данных, покупает небольшого нового участника рынка, которого он рассматривает как компанию-инноватора на основе управления данных или обладающую доступом к ценным данным).
В сделке Facebook/WhatsApp74 невысокий оборот второй компании оказался ниже порогового значения нотификации. Тем не менее, несмотря на относительно небольшой размер WhatsApp, Facebook заплатила за нее 19 млрд, дол., намекая на ожидаемую ценность поглощения. В конечном итоге Европейская комиссия рассмотрела сделку по просьбе Facebook об анализе слияния по принципу «единого окна», чтобы не уведомлять антимонопольные органы нескольких стран и не иметь дела с разными пороговыми значениями и правилами. Член Европейской комиссии М. Вестейджер публично заявила по делу Facebook/WhatsApp:«He всегда размер оборота делает компанию привлекательной стороной сделки слияния. Иногда имеют значение именно активы. Это может быть клиентская база или даже массив данных... или ценность компании может заключаться в способности к инновациям. Слияние, участником которого является такого рода компания, очевидно, может оказать влияние на конкуренцию, даже если оборот компании не так высок, чтобы подпадать под пороговые значения. Таким образом, рассматривая только оборот, можно упустить важные сделки, которые подлежат анализу»75.
Возможный способ выявления слияний, стимулом которых является приобретение данных конкурента — введение дополнительного порогового значения — стоимости сделки, которая отражает высокую цену, которую покупатели готовы платить за активы, например, за данные. Более того, в ОЭСР уже обсуждалось76, что такие пороговые значения сделки помогут антимонопольным органам выявить «упреждающие» поглощения, цель которых удалить потенциальных создателей прорывных инноваций (некоторые из них создают инновации на основе данных).
Пороговые значения сделок приняты в США и Мексике и находятся на рассмотрении в других странах, например, в ФРГ. По рекомендации консультативного органа (Monopolkommission) Федеральное министерство экономики и энергетики77 опубликовало проект поправок к Закону против ограничений конкуренции, предложив новый порог сделок — 350 млн. евро в дополнение к нынешнему пороговому обороту. Введение порога величины сделки также обсуждается в ЕС. М.Вестейджер[80] подчеркнула важность правильного определения порогового значения для предотвращения нанесения вреда инновационным стартап-компаниям.
Библиография
Acquisti A., Taylor С., Wagman L. The Economics of Privacy // Journal of Economic Literature. 2016, no 2. Available at: http://dx.doi.org/10.2139/ssrn.2580411 (дата обращения: 25.07.2016)
Balto D., Lane M. Monopolizing Water in a Tsunami: Finding Sensible Antitrust Rules for Big Data. Available at: http://ssrn.com/abstract=2753249 (дата обращения: 4.10.2016)
Bauer M. Big Data: New Frontier for Competition Law / IBC Competition EU Competition Law Conference. Available at: http://oecdshare.oecd.org/daf/competition/Knowledge%20Database/NonO- ECD%20events/IBC%20AdvancedCompLaw%20Brussels%20Feb2016/Michael%20Bauer.pdf (дата обращения: 7.08.2016)
Crofts L. Antitrust Watchdogs are Realizing Power of ‘Big Data7 EU Data Chief Says / Mlex Global Antitrust. 2016. Available at: http://www.mlex.com/GlobalAntitrust/DetailView.aspx?cid=783261&siteid =190&rdir=1 (дата обращения: 30.09.2016)
De Mauro A., Greco M., Grimaldi M. A Formal Definition of Big Data Based on its Essential Features // Library Review, 2016, no 3, pp.122-135.
Engels B. Data Portability among Online Platforms // Internet Policy Review. 2016, no 2. Available at: http://policyreview.info/articles/analysis/data-portability-among-online-platforms (дата обращения: 27.09.2016)
Gal M., Rubinfeld D. Hidden Costs of Free Goods: Implications for Antitrust Enforcement. Available at: http://awards.concurrences.com/IMG/pdf/galrubinfeld_final2.pdf (дата обращения: 16.08.2016) Guniganti P. Laitenberger: DG Comp May Enforce in E-Commerce // Global Competition Review. 2016. Available at: http://globalcompetitionreview.com/news/article/41886/laitenberger-dg-comp-may- enforce-ecommerce/ (дата обращения: 22.09.2016)
La hart J. How Wal-Mart’s Store Closings Paint Wider Retail Picture: Shift to Online Sales Shows Difference between Retailing’s Haves and Have-Nots. Wall Street Journal. January 15, 2016. Available at: http://www.wsj.com/articles/how-wal-marts-store-closings-paint-wider-retail-picture-1452871692 (дата обращения: 3.11.2016)
MacLennan M. Netherlands Starts Big Data Probe // Global Competition Review. 2016. Available at: http://globalcompetitionreview.com/news/article/41893/netherlands-starts-big-data-probe (дата обращения: 12.08.2016)
MarmerV., ShneyerovA., Kaplan Li. Identifying Collusion in English Auctions. February 26 2016. Available at: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2738789 (дата обращения: 17.11.2016) Schepp N., Wambach A. On Big Data and its Relevance for Market Power Assessment // Journal of European Competition Law & Practice. 2016, no 2, pp. 120-124. Available at: http://jeclap.oxfordjournals.org/content/7/2/120.abstract (дата обращения: 3.12.2016)
Sokol D., Comerford R. Does Antitrust Have a Role to Play in Regulating Big Data? / Cambridge Handbook of Antitrust, Intellectual Property and High Tech. Cambridge (Mass): Harvard University Press, 2016 //Available at: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2723693 (дата обращения: 6.10.2016).
Stucke M., Ezrachi A. Virtual Competition. The Promise and Perils of Algorithm-Driven Economy. Cambridge (Mass.): Harvard University Press, 2016. 368 pp. Available at: http://www.hup.harvard.edu/cata- log.php?isbn=9780674545472 (дата обращения: 12.12.2016)
Stucke M., Grunes A. Big Data and Competition Policy. Oxford: University Press, 2016. Available at: https://global.oup.com/academic/product/big-data-and-competition-policy9780198788133?cc=fr&lang=en& (дата обращения: 10.10.2016)
Похожие статьи
Филиппова С.Ю.
Мисостишхов Т.З.
Солдатова Вера Ивановна
Савенко Наталья Евгеньевна
Моисей Абрамович Скляр
Камила Владимировна Кудрявцева