This article is published under a Creative Commons license and not by the author of the article. So if you find any inaccuracies, you can correct them by updating the article.

Ментальный лексикон: где же место морфологии?



Мария Васильева
Published: Jan. 1, 2014
Latest article update: Sept. 13, 2022
This article is published under the license




Abstract
Репрезентация морфологии в ментальном лексиконе является одной из актуальных проблем современной психолингвистики. В данной работе делается попытка дать максимально исчерпывающий обзор моделей ментального лексикона, в которых отражена морфемная структура слова, а также поведенческих методик, направленных на проверку данных моделей. Поскольку на данный момент ни одна из моделей не является общепризнанной, мы приводим некоторые основные эффекты, связанные с морфологией, которые были получены в экспериментальных исследованиях и объяснение которых должно быть заложено в идеальную модель.
Keywords
Ментальный лексикон, психолингвистика, морфемная структура слова
Введение
Ментальный лексикон (англ, mental lexicon), далее — МЛ, как понятие, по-видимому, восходит к термину ментальный словарь (англ, mental dictionary), предложенному Э.Трейсман в ее неопубликованной диссертации ((Treisman, 1961), цит. по (Coltheart et al., 2001)) для обозначения хранилища слов с их значениями в памяти человека. Если следовать метафоре словаря, то в МЛ должны быть свои «словарные входы» и «словарные статьи», в которых содержались бы сведения о произношении, написании, значении и грамматических характеристиках слова, которые активировались бы, когда человек читает или слышит определенное слово. К сожалению, неудобство переноса устройства словаря на МЛ состоит в том, что единица словаря — лексема, являющаяся абстракцией от своих словоформ, — непосредственно не наблюдается в речи. Поэтому встает вопрос, какие значимые языковые единицы хранятся в МЛ: словоформы, морфемы или же и те, и другие, а также как осуществляется доступ к словарной статье МЛ. Кроме того, исследователю МЛ важно понимать, как организовано само хранение языковых единиц, связаны ли они каким-нибудь образом между собой. Если при ответе на второй вопрос большинство склоняется к устройству МЛ по принципу семантической сети, в узлах которой располагаются языковые единицы, то при ответе на первый круг вопросов до сих пор не было выработано единой точки зрения.
В первой главе данного обзора представлены различные варианты того, как в МЛ может быть репрезентирована морфемная структура слова. Во второй главе рассматриваются основные поведенческие методики, нацеленные на изучение строения МЛ и доступа к нему. В третьей главе приводятся результаты исследований с применением этих методик и обсуждение их в свете описанных моделей.
Модели ментального лексикона
В первой части этой главы будут рассмотрены ранние модели МЛ (модель лексического поиска, логогенная модель, модель интерактивной активации), в которых репрезентации морфологии уделялось сравнительно мало внимания. Во второй части главы мы перейдем к рассмотрению собственно морфологически ориентированных моделей МЛ.
Хранение и опознание мономорфемных слов в ментальном лексиконе
Модель лексического поиска
Модель лексического поиска (англ, lexical search model), разработанная К. Форстером (Forster, 1976), предполагает, что в памяти человека для каждого слова хранятся несколько репрезентаций: фонологический облик, графический облик, значение, а также основная грамматическая информация (частеречная принадлежность). Параллельно с этими репрезентациями в отдельном «файле» хранятся единицы доступа к МЛ: орфографические репрезентации слова для чтения, фонологические репрезентации для восприятия речи на слух и семантико-синтаксические репрезентации для порождения речи и письма. Каждая репрезентация в файле, хранящем единицы доступа, связана с основными репрезентациями лексических единиц МЛ.
Данная модель была наиболее подробно разработана на уровне файлов доступа для орфографических репрезентаций. По Форстеру, орфографические репрезентации в файле единиц доступа организованы согласно форме и частотности слова: слова, у которых на одних и тех же местах находятся одинаковые буквы, будут храниться вместе в специальных подфайлах. Например, для английского языка в одном подфайле с меткой sp### (знак решетки в данном случае обозначает любую букву, количество решеток соответствует количеству букв, различному для всех слов этого подфайла) будут храниться слова: spade ‘лопата’, spank ‘хлопок’, spoil ‘портить’, speed ‘скорость’ и т.д. Репрезентации, являющиеся единицами доступа, хранятся в порядке убывания частотности.
Когда человек видит слово, сначала происходит извлечение информации о его написании. Затем запускается циклический процесс поиска, начиная с наиболее частотных слов и постепенно двигаясь до искомого по убыванию частотности. В процессе поиска происходит сравнение репрезентаций, хранящихся в файле, и графического облика слов. Когда они совпадают, открывается доступ к основному хранилищу. Подобный частотно-ориентированный поиск объясняет, почему частотные слова распознаются быстрее низкочастотных слов.
Поскольку у каждого слова есть два вида репрезентаций (для доступа и для хранения), то в файле с единицами доступа могут храниться только частичные репрезентации. Например, для слова rhinoceros ‘носорог’, с точки зрения автора данной модели, достаточно хранить только сегмент rhin. Это согласуется с экспериментальными данными о восприятии слов на слух: слова распознаются в тот момент, когда они становятся отличимыми от других слов, хранящихся в МЛ, то есть в тот момент, когда была достигнута точка распознания (англ, recognition point) (Marslen-Wilson, 1989). Концепция частичной репрезентации также основывается на том факте, что желательным свойством любой системы обработки языковой информации является очень быстрый доступ к МЛ по увиденному слову. Иначе, при медленной обработке читателю было бы сложно следить за сообщением.
В качестве кандидатов в частичные репрезентации наряду с традиционными единицами, такими как корень и первый слог слова (Taft, Forster, 1976), рассматривалась единица, не выделявшаяся ранее в традиционной лингвистике, базовая орфографическая слоговая структура (англ, basic orthographic syllabic structure), или сокращенно БОСС (BOSS) (Taft, 1979а). М. Тафт определяет БОСС как группу идущих подряд букв слова, начиная с первой буквы корня и кончая кластером согласных, следующих за первой гласной корня. При этом получившаяся единица должна образовывать хотя бы псевдослово, то есть подчиняться типичным орфографическим правилам данного языка и легко читаться, но ей необязательно быть семантически осмысленной. Так, например, для слов lantern ‘фонарь’ и rhubarb ‘ревень’ БОССами являются цепочки букв lant и rhub соответственно. Из примеров видно, что БОССы не обязаны совпадать ни с корневой морфемой, ни с первым слогом.
Логогенная модель
Логогенная модель опознания слова (англ, logogen model) (Morton, 1969, 1970) подразумевает одновременное хранение полной лексической информации и отдельных репрезентаций слова, предназначенных для доступа к МЛ. В данной модели выделяются два компонента: логогенная система, соответствующая уровню доступа, и когнитивная система, соответствующая уровню хранения полной лексической информации. Как и Форстер, Дж. Мортон уделяет основное внимание проблеме доступа к МЛ и почти не акцентируется на строении когнитивной системы.
Логогенная система, обеспечивающая доступ к МЛ, состоит из логогенов (англ, logogen), как видно из ее названия. Активация логогена является пассивной ответной реакцией на стимульное воздействие. Как только информация, хранящаяся в логогене (фонологическая / семантическая / морфологическая), совпадает с частью стимула, происходит увеличение уровня активации языковой единицы. Кроме того, в логогене учитываются сведения о частотности слова и наиболее распространенных контекстах, в которых данное слово встречается.
Каждый логоген характеризуется специфическим критическим порогом активации, соответствующим тому объему активации, который необходим для опознания слова. Порог тем меньше, чем слово частотнее. Как только происходит полное совпадение информации, содержащейся в слове-стимуле, и информации, хранящейся в логогене, достигается необходимый порог активации для доступа к когнитивной системе. Поскольку логогенная система активируется пассивно, то процесс активации задействует одновременно все логогены, в отличие от модели лексического поиска, в которой за единицу времени доступ предоставляется только к одной репрезентации слова.
Модель интерактивной активации
Модель интерактивной активации (англ, interactiveactivation model), разработанная Дж. МакКлеллан- дом и Д. Румельхартом (McClelland, Rumeihart, 1981) в рамках коннекционизма’, предполагает несколько уровней репрезентации языковой информации: уровень отдельных признаков (тех элементов, из которых составлены буквы: например, для буквы «н» — это две вертикальные («|») и одна горизонтальная («-») линии), уровень букв и уровень слов (при восприятии цепочки букв все буквы обрабатываются параллельно и одновременно). Каждой воспринимаемой единице соответствует свой узел на каждом уровне. Узлы могут быть связаны друг с другом, то есть быть «соседями»: тогда между ними устанавливаются отношения, замедляющие активацию, если между ними нет непосредственной связи, или возбуждающие, если связь есть. Активация одного узла ведет к активации соседних узлов. Но нисходящее и восходящее взаимодействие возможно только между смежными уровнями.
Уровень активации словесной репрезентации вычисляется как функция двух переменных: частотности слова и степени сходства его графического облика с графическими обликами других слов. Чем выше уровень активации одного слова, тем сильнее он может подавлять активацию репрезентаций других слов.
Согласно коннекционистскому подходу, система связей в лексической системе является следствием частой совместной встречаемости определенных структур в языке (Sandra, 1994). Если некоторые перцептивные единицы (например, буквы) часто встречаются вместе, то связи между ними будут тем сильнее, чем чаще они употребляются рядом. Так, связи между буквенными репрезентациями, которые образуют кластер, будут сильнее, чем связи между буквами, которые редко следуют друг за другом на письме в данном языке. То же правило действует и для единиц разных уровней. Например, если некоторая последовательность букв чаще выполняет определенную функцию или выражает определенное значение, то связи между этой последовательностью букв и этой функцией / этим значением будут активированы скорее, чем связи-конкуренты.
Морфология в ментальном лексиконе
Большинство моделей, описывающих потенциальную архитектуру МЛ, не проводит различия между словоизменительной и словообразовательной морфологией, если не оговорено противного.
Цельнословное хранение
Гипотезу о хранении многоморфемных слов в МЛ целиком (англ, full listing account) и, соответственно, цельнословном доступе к нему приписывают Б. Батеруорту

(Butterworth, 1983; см., например, введения в работах Dohmes et al. (2004); Longtin, Meunier (2005); Kaza- nina et al. (2008) и т. д.). Частным случаем цельнословного подхода является гипотеза независимых входов (англ, independent unit hypothesis) (Manelis, Tharp, 1977), согласно которой слово, состоящее из нескольких морфем, имеет собственный независимый лексический вход, как и мономорфемные слова, а доступность входа обуславливается частотностью данной словоформы (см. рисунок 1). Однокоренные слова и формы одного слова при этом связаны в той же степени, что и любые другие слова.
Морфемная структура слова специально не отражена также и в коннекционистских моделях МЛ (Seidenberg, 1987; Plaut, Gonnerman, 2000; McClelland, Patterson, 2002), где она является лишь неизбежным побочным эффектом усвоенных системных отношений между планом содержания и планом выражения.
Другой вариант хранения многоморфемных слов целиком подразумевает установление особых связей между однокоренными словами или формами одного слова, что может быть реализовано на уровне целых словоформ, так и отдельных фонем/графем. В первом случае связи между словоформами одного слова подразумевают парадигматическую организацию МЛ. Ее частным случаем является гипотеза сателлитного устройства ментального лексикона1 (Коннекционизм (англ. connectionism) — один из подходов в когнитивной науке, направленных на моделирование человеческого познания, при котором ментальные явления описываются при помощи сети связанных между собой простых элементов.)2 (Перевод предложен И.А. Секериной (1997).) (англ, satellite entries hypothesis), которая разрабатывалась изначально как модель представления падежной системы (Lukatela et al., 1980). Предполагается, что хотя все словоформы лексемы имеют свой отдельный вход, они хранятся в виде кластера. В его центре находится форма номинатива единственного числа, который функционирует как ядро репрезентации существительного и аккумулирует информацию о частотности. Косвенные же падежи не имеют своей частотной характеристики и группируются, как спутники, вокруг ядра. Л. Б. Фельдман и К. Фаулер (Feldman, Fowler, 1987) дополнили эту модель, охарактеризовав связи между словоформами (см. рисунок 2). Согласно их концепции, ядро связано теснее со своими спутниками, чем спутники между собой. За счет этого при активации ядра происходит активация спутников, и, наоборот, при активации одного из спутников активируется ядро. Однако при активации одного из спутников активация других спутников либо не произойдет вовсе, либо будет очень слабой.
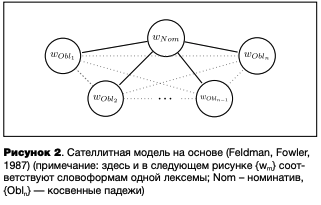
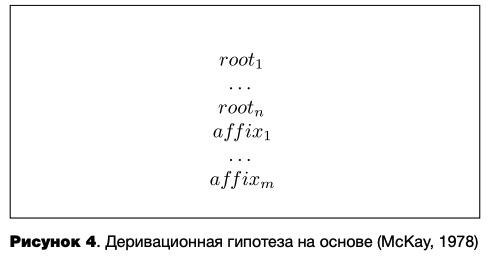
Теоретически сателлитное устройство возможно и при наличии частотных характеристик у всех словоформ, что предлагалось для валлийского словоизменения существительных с чередованием начальных согласных (мутациями) (Воусе et al., 1987). В их модели все формы слова, как исходная (немутированная), так и другие (мутированные), связаны друг с другом связями одной силы (см. рисунок 2). Сателлитного устройства словообразовательной морфологии, насколько известно автору, в литературе не представлено.
Второй способ установления связей между словами был предложен Дж. Байби (Bybee, 1985; 1995). Согласно ее концепции, словоформы, хранящиеся в словаре, связаны друг с другом благодаря наборам установленных лексических отношений идентичности и сходства фонологических и семантических признаков. За счет такого способа представления информация о морфемной структуре слова вырисовывается сама собой, хотя сами словоформы на морфемы специально не поделены. Лексические отношения между словами могут различаться по своей силе в зависимости от частотности, а также от типа и количества общих признаков. Более слабые семантические связи, как правило, наблюдаются между нерегулярными формами одного слова (например, англ, bring‘принести’ — brought ‘принес’). На основе групп слов со сходными паттернами семантических и фонологических отношений возникают обобщения, или схемы, которые затем могут применяться для анализа и построения новых слов.
В целом, подход к словоизменительной морфологии, при котором как регулярные, так и нерегулярные формы слова хранятся в памяти целиком (Bybee, 1995; McClelland, Patterson, 2002), в рамках исследований ментальной грамматики получил название односистемного.
Несмотря на такие достоинства, как цельнословный доступ, который принято считать менее затратным по сравнению с морфемным анализом, и сравнительно меньшее количество правил ментальной грамматики по сравнению с другими подходами, модели, подразумевающие отдельные вхождения для каждой словоформы, не являются оптимальными с точки зрения объема хранящейся информации (все дериваты всех корней и все формы одного слова).
Поморфемное хранение
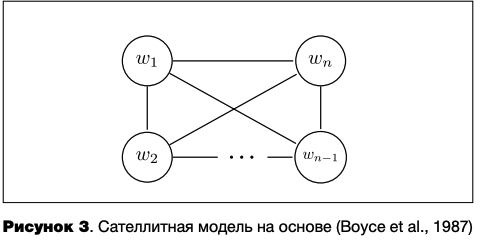
Альтернатива неэкономного хранения всех возможных дериватов одного корня — хранить только морфемы. Но тогда встает вопрос, хранятся ли все морфемы отдельными списками или морфемы, которые могут встретиться друг с другом в пределах одного слова, связаны в МЛ особыми связями. В первом случае речь идет о деривационной гипотезе (англ, derivational hypothesis) (McKay, 1978), которая подразумевает, что морфемы хранятся без связей между собой (см. рисунок 4), а за их правильное склеивание в рамках одного слова отвечают специальные правила ментальной грамматики. В пользу хранения морфем говорят оговорки типа перестановки двух морфем или неправильной локализации морфемы в речи (например, англ, point outed вместо pointed out ‘указал’) (Downing, 1977). Недостатком поморфемного хранения языковой информации является перегружение ментальной грамматики правилами, которые бы описывали корректное соединение морфем в единую словоформу, а также правилами, которые бы отвечали за вычисление значения слова из значений корня и присоединяющихся к нему аффиксов. Если бы в семантике соблюдался принцип композициональности, требующий, чтобы значение суммы частей складывалось из суммы значений соответствующих частей, то значение слова всегда можно было бы вывести из суммы значений составляющих его морфем. Однако словообразовательные аффиксы часто склонны нарушать этот принцип, ср., например, англ, department' отделение, кафедра’ и government ‘правительство’ с depart ‘отправляться, отступать’ и govern ‘управлять, руководить’ (Marslen-Wilson et al., 1994).
Другое слабое место данной гипотезы связано с опознанием псевдоаффиксальных слов3 (Под псевдоаффиксальным словом понимается такое слово, некоторая часть которого случайно совпадает с существующим в языке аффиксом.) 4 (В данном случае основа понимается не в лингвистическом смысле (часть слова без словоизменительных показателей), а как некоторая далее неделимая часть слова, несущая на себе лексическое значение и присоединяющая к себе различные аффиксы. Она совпадает с корнем или с последовательностью нескольких морфем, образующих семантически непрозрачный комплекс.) (ср. ге- как элемент корня в англ, relish ‘наслаждаться’ и ге- как приставку в reread ‘перечитывать’). Если морфемный анализатор, обеспечивающий доступ к МЛ, действуя слепо, выделяет в слове все возможные аффиксы, для псевдоаффиксальных слов приходится предполагать ложную морфемную декомпозицию, не выделяющую существующего корня или выделяющую незарегистрированное сочетание морфем, а затем дополнительную процедуру реанализа. Такое решение, не представляющееся оптимальным с точки зрения затрат при доступе, было отражено в гипотезе обязательного отделения приставки (англ, prefix-stripping hypothesis), разработанной в рамках модели лексического поиска (Taft, Forster, 1975; Taft, 1981). В этой модели также реализовано обязательное отделение словоизменительного, но не словообразовательного суффикса (Taft, 1979b).
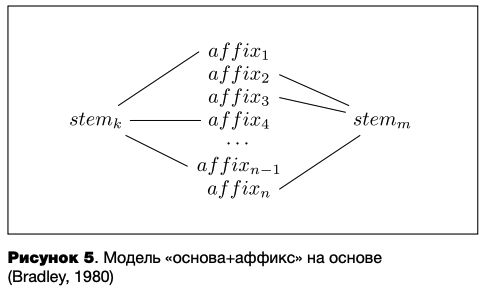
Уменьшить излишнюю нагрузку на ментальную грамматику, являющуюся следствием деривационной гипотезы, призвано введение дополнительных связей между морфемами, образующими существующие слова, в модели основа+аффикс (англ, stem+affix model) (Bradley, 1980) (см. рисунок 5), а также целостное хранение семантически непрозрачных комплексов (Marslen-Wilson et al., 1994).
Поскольку словоизменительные аффиксы в отличие от словообразовательных характеризуются относительно широкой сочетаемостью, относительной регулярностью и предсказуемостью значения, для них декомпозиция и отдельное хранение являются более правдоподобными. Соответственно, возникают модели, где словообразовательные дериваты хранятся целиком, а формы слова — в «разобранном» виде. Такой подход реализован для финского языка в рамках модели SAID (англ. Stem Allomorph / Inflectional Decomposition — декомпозиция по границе основы и окончания), где предусмотрен морфемный анализ для словоизменительной морфологии, но не словообразовательной (Hyönä et al., 1995).
Для нерегулярных форм слова при поморфемном хранении приходится предполагать цельное хранение в виде исключения либо вводить особые нелинейные правила, оперирующие чередованиями. В первом случае речь идет о так называемом двусистемном подходе, при котором правильные и неправильные формы относятся к разным уровням хранения и обработки языка (Pinker, 1999; Huang, Pinker, 2010). Нерегулярные формы, как и при односистемном подходе, хранятся в памяти целиком, а регулярные формы образуются по специальным правилам ментальной грамматики. Во втором случае имеется в виду модель конкуренции правил (англ, rule competition model) Ч. Янга (Yang, 2002). В данном случае основа понимается не в лингвистическом смысле (часть слова без словоизменительных показателей), а как некоторая далее неделимая часть слова, несущая на себе лексическое значение и присоединяющая к себе различные аффиксы. Она совпадает с корнем или с последовательностью нескольких морфем, образующих семантически непрозрачный комплекс.
Кластерные модели
Гибридом поморфемного и цельнословного хранения выступают кластерные модели, в которых хранятся как все дериваты одного корня, так и сам корень, но не отдельные аффиксы. В частичном виде эта гипотеза представлена в работе Р. Станнерса с коллегами (Stanners et al., 1979), согласно которой доступ к английским приставочным дериватам, хранящимся целиком, осуществляется только после морфемного анализа. Модель П. Коле и коллег (Cole et al., 1986; Cole et al., 1989), разрабатывавшаяся для французского языка, предполагала линейную обработку слова слева направо, при которой приставочные слова опознаются целиком (в таком случае активация корня происходит после доступа к МЛ), а в суффиксальных словах, наоборот, доступ осуществляется после выделения корня при морфемной декомпозиции.
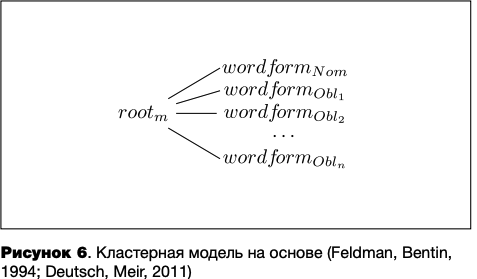
В чистом виде кластерная модель предлагается для иврита, где словообразовательные и словоизменительные производные группируются вокруг своего корня (Feldman, Bentin, 1994; Deutsch, Meir, 2011) (см. рисунок 6).
Двухуровневые модели морфологии
В двухуровневых5 (Двухуровневыми мы называем модели, в которых информация о морфемном строении слова дублируется на двух связанных друг с другом уровнях. Всего уровней при такой архитектуре может быть гораздо больше.) моделях постулируется сосуществование уровня морфем и уровня слов, связанных между собой специальными связями. Основные различия между этими моделями кроются в выборе ключа доступа к МЛ (комплекс выделенных с помощью морфемного анализа морфем и/или целое слово), а также расположение уровня морфем и уровня слов относительно семантического уровня.
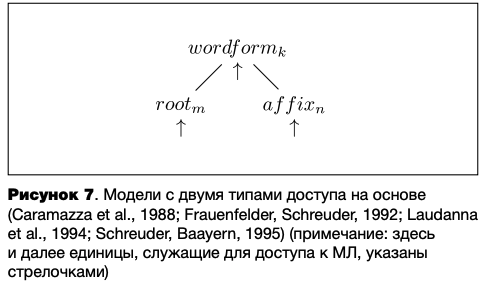
Двухуровневые модели с двумя типами доступа. В модели расширенной адресной морфологии (англ. Augmented Addressed Morphology, ААМ) цельнословное опознание осуществляется для знакомых слов, а морфемный анализ — для незнакомых слов (Caramazza et al., 1988) (см. рисунок 7). В более поздней версии той же модели сфера действия морфемного анализа была расширена до частотных аффиксов, редко встречающихся в псевдоаффиксальных словах (Laudanna et al., 1994).
Модель морфологических скачек (англ. Morphological Race Model) предполагает, что при опознании слова параллельно запускаются два процесса: один отвечает за построение словоформы напрямую из орфографических (или фонологических) единиц и поиск ее значения на семантическом уровне, а другой сначала выделяет из цепочки букв (звуков) морфемы, а затем пробует получить из значений этих морфем интерпретацию всего слова (Frauenfelder, Schreuder, 1992). В зависимости от того, на какой из двух процессов уйдет меньше времени (если оставаться в рамках метафоры скачек, кто первый прибежал), доступ к МЛ будет цельнословным или за счет морфем. Но в любом случае слово будет опознано максимально быстро, что является значительным достоинством в особенности для понимания устной речи. Однако такая модель требует очень много ресурсов как для хранения языковой информации, так и для ее обработки.
В качестве компромисса между экономией ресурсов и скоростью доступа можно рассматривать модель, в которой два типа репрезентаций хранятся только для частотных слов (Schreuder, Baayern, 1995).
Двухуровневые модели с одним типом доступа. Двухуровневые модели с одним типом доступа возникли как попытки ввести в модель интерактивной активации морфемный уровень, который можно было поместить непосредственно после орфографического и/или фонологического уровней до уровня слов либо между уровнем целых слов и семантическим уровнем. Модели первого типа принято называть сублексическими (англ, sublexical models), а модели второго типа — супралексическими (англ, supralexical models).
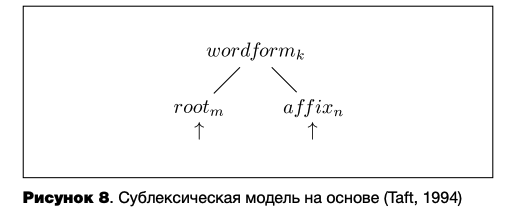
При сублексическом подходе при опознании сначала осуществляется морфемный анализ, а затем выделенные морфемы при наличии связей между ними обратно объединяются в целостную единицу, у которой прописано свое значение на семантическом уровне (Taft, 1994) (см. рисунок 9). Благодаря такой архитектуре не возникает противоречия между обязательной декомпозицией и некомпозициональным значением семантически непрозрачных комплексов. Кроме того, поскольку отдельные морфемы также имеют свои узлы со значением на семантическом уровне, то обработка незнакомых слов, содержащих незнакомые единицы, будет успешной. При сублексической модели допускается ошибочное разложение на морфемы псевдоаф- фиксальных слов, однако оно качественно отличается от сходного процесса в модели лексического поиска. В последней процедура морфемного анализа является линейной слева направо, а цельнословный реанализ начинается только после того, как после декомпозиции не было найдено соответствующего слова. В сублексической модели, напротив, одновременно активируется как представление целого псевдоаффиксального слова, так и выделенных в нем морфем. Например, при анализе английского слова corner ‘угол’ (внешне первая часть этого слова похожа на одноморфемное слово сот ‘кукуруза’, а вторая — на суффикс -er) одновременно активируются три возможных единицы: corner, сот и -er, что приводит к конкуренции между первыми двумя, а затем к победе первой из них.
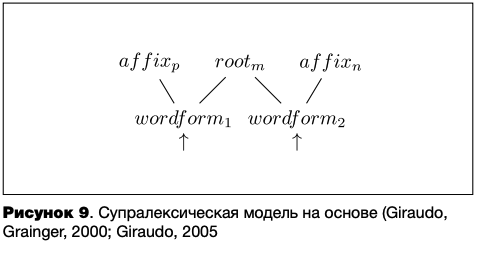
В супралексической модели (Giraudo, Grainger, 2000; Giraudo, 2005) доступ к МЛ является цельнословным, информация же о морфемной структуре слова предоставляется только после его опознания (см. рисунок 9). Достоинство супралексической модели по сравнению с сублексической состоит в том, что она оказывается более чувствительной к частотности целого слова по сравнению с частотностью отдельных морфем, а также к количеству слов-соседей и размеру псевдосемьи6 (Соседями (англ. neighbors) некоторого слова принято называть те слова, которые отличаются от данного на одну букву (напрмер, вечер и ветер). Под размером же псевдосемьи (англ. pseudo-family size) некоторого слова понимается количество слов, в которых начальные буквы/звуки совпадают с данным, например, в псевдосемью французского глагола porter ‘нести’ попадают такие слова, как porte ‘дверь’, portrait ‘портрет’, portugais ‘португальский’ и т. д. (Voga, Giraudo, 2009).) , которые потенциально могут оказывать отрицательное воздействие на активацию опознаваемого слова. В частности, данная модель предсказывает большую активацию однокоренных слов при постлексической активации морфем, составляющих частотное слово по сравнению с низкочастотным. Тем не менее, ее слабым местом остается обработка новых слов.
Модели с леммами
Во всех предыдущих моделях, фокусировавшихся на способах репрезентации морфологии, другие характеристики слова (семантические, грамматические) присоединяются непосредственно к хранящимся в МЛ словам и/или морфемам, которые, в свою очередь, непосредственно связаны с уровнем отдельных звуков / букв. Правомерность такого подхода отстаивалась, например, А. Карамацца и М. Миоццо (Caramazza, Miozzo, 1997). Однако ряд авторов придерживаются иной точки зрения, согласно которой в архитектуре МЛ должны быть заложены дополнительные уровни, единицами хранения на которых являются абстрактные единицы. При этом для описания вводимых промежуточных единиц хранения используются лингвистические термины {лексема, лемма) в нетрадиционных для лингвистики употреблениях, варьирующихся от исследователя к исследователю.
В модели М. Аллена и У. Бэдекера (Allen, Badek- ker, 1999, 2002; Badecker, Allen, 2002) на уровне лексем хранятся отдельные морфемы и нерегулярные формы (их фонологические репрезентации), а на уровне лемм — абстрактные представления для корня и его алломорфов, возникающих в нерегулярных словоформах. Как уровень лексем, так и уровень лемм связаны с представлениями семантического уровня. Также в данном подходе допускается хранение двух одинаковых фонологических репрезентаций омонимичных морфем на лексемном уровне в отличие от подходов, изложенных ниже.
Сходное понимание леммы представлено в работе Д. Крепальди с коллегами (Crepaldi et al., 2010). В этой модели, разработанной для объяснения процессов понимания, есть морфоорфографический уровень морфем, орфографический уровень словоформ, уровень лемм и семантический уровень; лемма при этом является абстрактным представлением всех форм одного слова (лексемой в чисто лингвистической терминологии), но не словообразовательных дериватов, и открывает доступ к значению слова.
В модели распространяющейся активации (англ. spreading-activation model) (Roelofs, 1992; Roelofs et al., 1998; Levelt et al., 1999), изначально разрабатывавшейся для описания порождения, в МЛ выделяется уровень слогов, уровень отдельных звуков, уровень морфофонологического облика слова — лексем (по сути — отдельных морфем), затем синтаксический уровень, на котором представлены леммы для каждой лексемы и ассоциированная с ними грамматическая информация, уровень концептов, аккумулирующих семантическую информацию о соответствующих леммах. Помимо постоянной грамматической информации (например, род для существительных) на синтаксическом уровне для леммы лексемы указывается набор потенциальных грамматических значений словоизменительных аффиксов, сочетающихся с данным типом основы (например, число и падеж для существительных). Отображение между концептами, леммами и морфемами не является взаимно однозначным соответствием: одной лемме могут соответствовать несколько морфем (сложные слова, формы слова), одному концепту могут соответствовать две леммы (случай английских глаголов типа look up ‘посмотреть’). Поскольку словоизменительные показатели не имеют собственных лемм, они отображаются на синтаксическом уровне в лемму основы слова, в котором они встретились. Нерегулярные формы, не делящиеся на морфофонологическом уровне, имеют такие же репрезентации лемм, как и регулярные формы. Для продуктивных словообразовательных аффиксов данный коллектив авторов допускает декомпозицию как на морфофонологическом уровне, так и на уровне лемм и концептов, непродуктивные же аффиксы не отделяются ни на каком уровне. Аналогично, не все сложные слова имеют две репрезентации, а лишь те, у которых наличие морфемной границы критично для формирования слоговых границ независимо от (непрозрачности значения (например, семантически непрозрачное нидерландское oogappel ‘дорогой малыш’ от oog ‘глаз’ и арреі ‘яблоко’ раскладывается на морфемы, поскольку слоговая граница проходит между морфемами — oog-ap-pel, а семантически более прозрачное aardappel ‘картофель’ aard ‘земля’ и арреі ‘яблоко’ — нет, поскольку в нем слоговые границы не зависят от морфемных — aar-dap-pel).
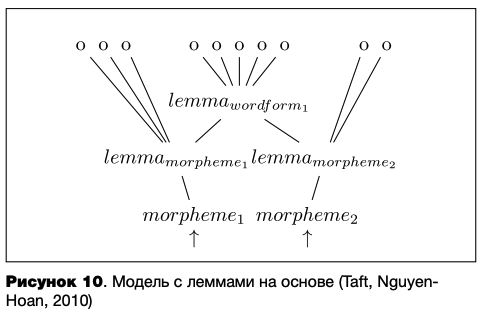
В подходе (Taft, Nguyen-Hoan, 2010), продолжающем сублексическую традицию, уровень лемм также является посредником между уровнем формы (орфографической / фонологической) и уровнем семантических и грамматических функций. На уровне формы хранятся репрезентации отдельных звуков / графем и морфемы, получаемые из них. Каждая морфема связана со своей леммой, леммы морфем, в свою очередь, связаны с леммами слов, в которых они встречаются (см. рисунок 10). Значение лемм на уровне функций представлено пучком признаков. При таком подходе на уровне форм не допускается хранения двух омонимичных морфем; вместо этого одной морфеме ставится в соответствие две леммы, связанные с различными наборами значений.
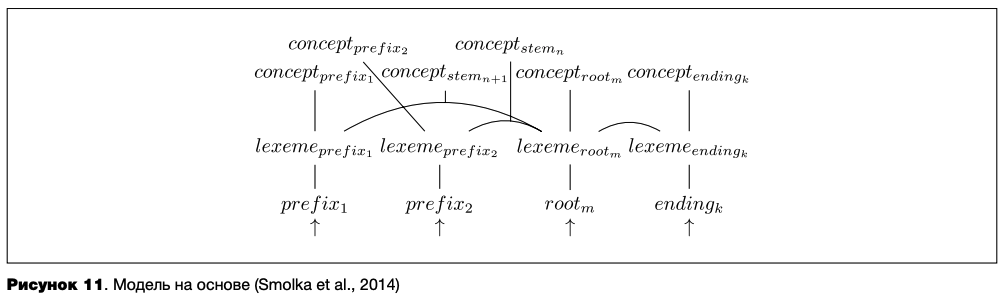
Наконец, в статье Е. Смолки с коллегами (Smolka et al., 2014) представлена модель с промежуточными репрезентациями, являющаяся аналогом модели «основа+аффикс» (см. рисунок 11). В ней предполагается три уровня: уровень форм, где хранятся целые морфемы; лексический уровень, где хранятся абстрактные представления этих морфем, причем морфемы, которые могут встретиться в рамках одного слова, связаны между собой; уровень концептов, где хранятся значения не только отдельных морфем, но и сочетаний корня со словообразовательными аффиксами — основ. Концепт основы связан со связью между составляющими ее морфемами, а не напрямую с ними.
Гибридные модели
К моделям, позиционирующим себя как содержащие леммы, примыкают гибридные модели, также содержащие уровень, промежуточный между формой и семантикой, но в отличие от предыдущих моделей, допускающие оба вида доступа (Diependaele et al., 2005; 2009; Giraudo, Voga, 2013; 2014). В них помимо морфографического уровня, на котором представлены орфографические / фонологические репрезентации отдельных морфем (морфом в терминологии Э. Жиродо и М. Bora), есть уровень целых словоформ (лексический в терминологии К. Дипендэла и его коллег) и уровень значения (семантический, по К. Дипендэла и его коллегам; концептуальный, по Э. Жиродо и М. Bora), а также уровень, промежуточный между ними.
В гибридной модели К. Дипендэла и его коллег этот уровень-посредник называется морфосемантическим и связывает цельнословные представления со значением их составляющих, морфемы же не имеют непосредственного выхода к семантике (см. рисунок 12).
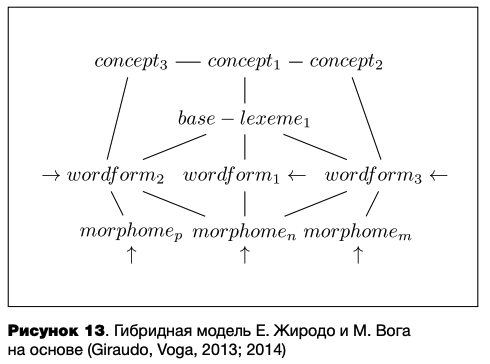
В гибридной модели Э. Жиродо и М. Bora, напротив, связаны с концептуальным уровнем как отдельные морфемы, так и целые слова. Слова, относящиеся к одной морфологической семье, на промежуточном уровне отображаются в одну «базовую лексему», совпадающую по форме с однокоренным мономорфемным словом, а для языков типа французского или английского являющуюся по сути корнем (см. рисунок 13).
Экспериментальные методы исследования ментального лексикона
Адекватность той или иной архитектуры МЛ по отношению к определенному языку можно проверить, в частности, экспериментально на носителях данного языка. Важный вклад в эту область вносят исследования усвоения языка детьми и формирования МЛ у людей, изучающих иностранный язык во взрослом возрасте, исследования строения МЛ у билингвов, а также данные о распаде языковой системы при различных типах афазий. Кроме того, слабые и сильные стороны потенциального устройства МЛ позволяют увидеть компьютерные модели, симулирующие процессы усвоения языка, понимания и порождения речи. Строение МЛ родного языка на взрослых здоровых носителях активно изучают с помощью как ней- ровизуализационных (ВП, МЭГ, фМРТ), так и поведенческих методов, но мы в своей работе ограничимся последними.
Методики, направленные на изучение понимания речи
Лексическое решение. Задача лексического решения (англ, lexical decision task) — одна из старейших и притом самых распространенных методик (Sandra, 1994). Задача испытуемого состоит в том, чтобы как можно быстрее определить, является ли предъявленная ему на экране компьютера цепочка букв или проигрываемая в наушники последовательность звуков словом его родного языка. При этом принято считать, что различия в скорости реакции на разные группы стимулов отражают особенности их хранения и доступа к ним. Среди факторов, влияющих на время опознания слова, таких как его длина, частотность, (не)однозначность, выделяют также и особенности морфемного строения, а также частотность отдельных морфем и размер морфологической семьи, к которой принадлежит слово-стимул.
К задаче лексического решения могут быть добавлены экспериментальные манипуляции со стимульным материалом, изменяющие, например, внешний облик зрительно предъявляемого стимула или определяющие взаимное расположение стимулов между собой.
Перестановка букв местами. Метод переставленных букв (англ, transposed letters или letter transposition) основывается на эмпирическом факте, что при чтении для опознания слова не требуется, чтобы все буквы слова были на своих местах. Соответственно в экспериментах, проведенных по этой методике, испытуемому предъявляется бессмысленная цепочка букв, полученная из настоящего слова перестановкой двух букв. В задаче лексического решения испытуемые чаще ошибаются в ответ на такой стимул-неслово и / или тратят дольше времени на размышление, чем когда им показывают обычное неслово. Для исследования морфологии наиболее интересным представляется сравнение опознания слов, в которых переставили местами две буквы на морфемной границе и внутри одной морфемы, так как если морфемный анализ является обязательным, нарушение первого типа будет иметь более серьезные последствия при обработке стимула, нежели нарушения второго типа.
Принудительная сегментация. В основе принудительной сегментации слова на потенциальные единицы МЛ лежит гипотеза о том, что если выделенные сегменты в слове совпадают с реально хранящимися в МЛ единицами, время реакции испытуемого в задаче лексического решения будет значимо меньше времени, затраченного на аналогичный вопрос при условии, когда выделенные сегменты не совпадают с хранящимися в памяти единицами. Технически сегментация может осуществляться с помощью пробела между единицами (Taft, 1979а; Lima, Pollatsek, 1983), дефиса (Libben, 2003), размера шрифта: строчный vs. прописной (Тай, 1979а), различного цвета шрифта (Rapp, 1992; Rouibah, Taft, 2001). При этом испытуемого просят не обращать внимания на «странный» способ предъявления.
Прайминг. Морфологический прайминг. Методика морфологического прайминга (англ, morphological priming) подразумевает предъявление однокоренного слова или другой формы той же лексемы до предъявления целевого слова, благодаря чему можно оценить силу связи между однокоренными словами и словоформами одной лексемы. Предполагается, что словоизменительные и словообразовательные дериваты, будучи праймами, ускорят опознание слова-стимула. Также обычно ожидается, что действие морфологического прайминга не будет отличаться или будет немного слабее эффектов, получаемых при использовании целевого стимула в качестве прайма. Положительный прайминг-эффект может быть использован как свидетельство в пользу сателлитного или кластерного устройства МЛ или/и же в пользу поморфемного разложения слова при его обработке. Морфологическая родственность слов подразумевает семантическое сходство и общий графический компонент при написании, однако морфологический прайминг нельзя свести исключительно к этим двум компонентам (свидетельства в пользу этого см. в Feldman, Fowler, 1987; Feldman, Moskovljevic, 1987; Feldman, 1990; Bentin, Feldman, 1990; Feldman, Bentin, 1994 и т. д.).
Методика морфологического прайминга представлена в двух вариантах. Когда прайм непосредственно предшествует стимулу, речь идет о методике с непосредственным предъявлением стимула. Если же временной интервал между праймом и целевым стимулом заполнен некоторым количеством филлеров7 (Филлеры — дополнительные стимулы, отвлекающие внимание испытуемого от экспериментальных.) , то используется методика с отложенным предъявлением стимула (англ, repetition priming). Количество филлеров обычно варьируется, но в среднем составляет около 10.
Помимо родственных слов в качестве праймов могут использоваться псевдослова с корнем целевого слова (Longtin, Meunier, 2005; Meunier, Longtin, 2007) и целевые слова с переставленными в них буквами (Dunabeitia et al., 2007; Rueckl, Rimzhim, 2011). 8 первом случае положительное воздействие псевдослова можно рассматривать как свидетельство возможности морфемной декомпозиции и наличия морфемного уровня в МЛ. Во втором случае больший прайминг-эффект при перестановке букв внутри морфемы прайма также может служить доводом в пользу морфемного анализа при обработке слова. Как аргумент в пользу представленности корней в МЛ используется прайминг корнем (Kehayia, Jarema, 1994; Järvikivi, Niemi, 2002).
Частным случаем морфологического прайминга является прайминг словом, содержащим тот же аффикс, что и целевое слово (Marslen-Wilson, Ford, Older, 1996; Smolik, 2010; VanWagenen, Pertsova, 2014). Положительный прайминг формы является более убедительным аргументом в пользу декомпозиции, чем морфологический прайминг.
Грамматический прайминг. Грамматический прайминг (англ, grammatical priming) подразумевает использование в качестве прайма слова другой грамматической категории, подходящего или не подходящего на роль зависимого или главного слова по отношению к целевому слову (Lukatela et al., 1983; Carello et al., 1988). Так, для существительных подходящим (англ, congruent) грамматическим праймом является согласующееся с ним прилагательное или предлог, управляющий тем падежом, в котором стоит целевой стимул; неподходящим грамматическим праймом будут, соответственно, несогласующееся прилагательное и предлог, управляющий другим падежом. Считается, что наличие положительного воздействия в первом случае должно отражать наличие предварительной активации релевантной грамматической информации в МЛ, когда, читая, человек переходит от одного слова к другому.
При кажущемся удобстве и простоте результаты, полученные в задаче лексического решения, следует использовать с осторожностью, поскольку время реакции может отражать не только и не столько время, необходимое на обработку и опознание стимула, сколько компонент, связанный с принятием решения. Так, одни и те же испытуемые одни и те же стимулы могут одинаково оценивать как слова / неслова только в 83 % случаев; воспроизводимость же значений времени реакции еще ниже (Diependaele et al., 2012). Причем согласованность в ответах выше для неслов (90%), чем для слов (76%). По мнению авторов статьи, при принятии решения о статусе увиденной цепочки букв испытуемый опирается на два эталона — наивысшей и наименьшей степени сходства со словом: если стимул попадает в первую или вторую категорию, ответы «слово» в первом случае и «неслово» во втором будут даны максимально быстро, в промежуточных же случаях будет производиться дополнительная верификация или же даваться случайный ответ. Соответственно, получаемые экспериментально различия по времени реакции в зависимости от частотности слова могут быть следствием не организации МЛ, а процедуры принятия решения, так как высокочастотные слова попадают в первую категорию, а низкочастотные — во вторую. Кроме того, время реакции на одни и те же слова может меняться в зависимости от характера используемых псевдослов / неслов (Вааует, 2014).
Постепенная демаскировка. Методика постепенной демаскировки (англ, progressive demasking), разработанная в исследовании Грейнджера и Сеги (Grainger, Segui, 1990), позволяет измерить время опознания слова, не используя псевдослова. Слово предъявляется на экране попеременно с последовательностью масок (###) несколькими циклами равной длительности (обычно используются временные интервалы в 200-300 мс), причем в каждом следующем цикле длительность предъявления слова увеличивается, а длительность предъявления масок уменьшается. Минимальное время предъявления слова, как и шаг между циклами, составляет 15 мс. При таких условиях предъявления у испытуемого складывается впечатление, что слово постепенно вырисовывается на фоне шума, создаваемого масками. Испытуемый дает ответ в тот момент, когда в состоянии распознать слово, нажимая на кнопку клавиатуры. Затем его просят записать то слово, которое он увидел. Постепенная демаскировка позволяет уменьшить объем информации, доступной в единицу времени, благодаря чему можно исследовать те эффекты, которые возникают на более ранних стадиях зрительного восприятия.
«Иллюзорные соединения». Данная методика основывается на известном в психологии внимания феномене иллюзорных соединений (англ, illusory conjunctions), или ошибок связывания (англ, feature conjunction errors), хорошо изученных в рамках исследовательского подхода, основанного на теории интеграции признаков Энн Трейсман (Трейсман, 1987). Эта теория зрительного внимания предполагает, что при восприятии объекта происходит параллельная обработка всех его признаков, таких как, например, цвет и форма, которые затем интегрируются в единый образ. При быстром тахистоскопическом предъявлении нескольких объектов человек может ошибочно связать выделенные признаки. Так, в эксперименте Трейсман при предъявлении цветных геометрических фигур у испытуемых возникали иллюзорные соединения формы и цвета объекта. Предположение автора статьи (Seidenberg, 1987) заключалось в том, что если существует сублексический уровень обработки слова, то структурные особенности стимула (слоговая / морфемная структура) будут оказывать влияние на характер связывания признаков. В качестве структурных особенностей стимула М. Зайденберг предложил использовать различный цвет букв предъявляемого слова, например THUNDER ‘гром’. В качестве зависимой переменной выступают ошибки связывания признаков. То есть его испытуемые, увидев двуцветное слово, должны были отчитаться о цвете контрольной буквы. Контрольная буква может располагаться либо перед границей между предполагаемой единицей доступа к МЛ и остальной частью слова, либо после нее. Так было выделено два типа ошибок связывания признаков: сохранение целостности единицы доступа (англ, preservation) и ее нарушение (англ, violation). Например, если слово burden предъявлено в виде BURDEN, а испытуемого спрашивают про цвет буквы D, то его ответ «красный» будет сохранять целостность слоговой единицы. Если же то же самое слово предъявлено в виде BURDEN и человеку задают тот же вопрос, то его ответ «синий» будет сохранять целостность БОСС. При наличии сублексического уровня, таким образом, можно ожидать большего количества ошибок по типу сохранения целостности единиц доступа.
Суждение об идентичности при разном шрифте. В экспериментах, основанных на этой методике (англ. cross case same — different task) (Dunabeitia et al., 2011), испытуемого просят оценить, идентична ли одна последовательность букв другой последовательности (англ, reference), предъявленной до этого. В целевой последовательности все буквы заглавные, а в «референциальной» последовательности все буквы строчные, как и в замаскированном прайме, который предъявляется по времени между ними. Испытуемого просят принимать решения о сходстве / различии, игнорируя разный шрифт и опираясь только на орфографию. Данная методика не требует лексической / семантической обработки слова и, следовательно, доступа к МЛ, что позволяет проверить при использовании в качестве прайма слов с переставленными буквами, является ли морфемный анализ обязательным.
Оценка грамматической правильности. Методика оценки грамматической правильности (англ. grammaticality judgement task) не является специфичной для этой области психолингвистики. При исследовании морфологии в МЛ испытуемого, как правило, просят оценить приемлемость изолированных псевдослов (Marjanovic et al., 2013) или псевдослов в контексте предложений (Huang, Pinker, 2010) по определенной шкале. Результаты подобных экспериментов позволяют изучить категориальную сочетаемость аффиксов, а также выявить продуктивные и непродуктивные модели словообразования и словоизменения.
Движения глаз. Распространенным методом при изучении понимания является запись движений глаз (англ, eye-tracking). При чтении текста испытуемым с помощью этого метода можно регистрировать количество и длину фиксаций на целевом слове. Целевые слова могут предъявляться изолированно или в контексте предложений.
В первом случае регистрацию движений глаз совмещают с задачей лексического решения. При этом испытуемому разрешается смотреть на каждый стимул столько времени, сколько потребуется, чтобы дать ответ (Hyönä et al., 1995; Kuperman et al., 2009). Соответственно, у него появляется возможность отводить взгляд, а потом снова фиксировать его на стимуле. Ожидается, что паттерны движений глаз могут зависеть от морфемной структуры слова и степени его семантической прозрачности.
Во втором случае к словам в стимульных предложениях могут применяться дополнительные экспериментальные манипуляции, такие как принудительная сегментация и морфологический прайминг. В отличие от задачи лексического решения при регистрации движений глаз используются только такие разделители, как пробел или дефис (Juhasz et al., 2009; Bertram et al., 2011). При морфологическом прайминге в рамках предложения морфологически связанный с целевым стимулом прайм размещается линейно до него (Paterson et al., 2011). При этом можно отследить тип и объем воздействия прайма на целевое слово в зависимости от степени семантической прозрачности и типа морфологической связи (словоизменительная / словообразовательная). Некоторым аналогом прайминга отдельной морфемой можно считать и метод границы (англ, eye-contingent boundary paradigm) (Lima, 1987; Deutsch et al., 2003; Kambe, 2004), разновидность методики, при которой предъявляемый текст меняется в зависимости от текущей позиции взгляда (англ. gaze-contingency paradigm). Как следует из его названия, этот метод подразумевает, что в определенном месте предложения размещается невидимая граница. Текст, находящийся за ней, меняется после пересечения взглядом этой границы. Как правило, эту границу располагают между двумя морфемами: одна из них предъявляется все время, а вторую вначале заменяют на ряд букв X или иную бессмысленную последовательность букв. С помощью этого метода можно проверить, извлекается ли парфовеальным зрением морфологическая информация, и если да, то какого типа и в каком объеме.
Принято считать, что регистрация движений глаз обладает большей экологической валидностью по сравнению с лексическим решением, так как последнее требует от человека принятия металингвистического решения, а кроме того, человек редко сталкивается с изолированными словами вне контекста (Ваауегп, 2014). Однако как показало исследование (Kuperman et al., 2013), между паттернами движений глаз при чтении и временем реакции в задаче лексического решения есть положительная корреляция. Тем не менее корреляция является значимой при сравнении результатов лексического решения с количеством и длительностью фиксаций, полученных при чтении только специально составленных нейтральных не очень длинных предложений, но не длинных абзацев. Таким образом, даже при записи движений глаз испытуемый обычно находится в довольно далеких от реальности экспериментальных условиях.
Методики, направленные на изучение порождения речи
Описанные выше методики направлены на изучение обработки языковой информации и ее хранения в МЛ через восприятие. Другой возможный путь — выявить по возможности те элементы, из которых «склеивается» слово при порождении, если оно не хранится в памяти целиком.
Называние. Базовой методикой при изучении порождения речи является называние (англ, naming task) (Feldman, Prostko, 2002). Задача испытуемого состоит в том, чтобы как можно быстрее озвучить предъявленное ему слово либо назвать предмет, изображенный на картинке. В качестве зависимой переменной, измеряемой в ходе эксперимента, используется время от начала предъявления стимула до произнесения слова человеком.
Более утонченным вариантом этой методики является обусловленное называние (англ, go / по go пат- ing), устный аналог лексического решения, когда человеку требуется озвучивать только предъявляемые ему слова и игнорировать неслова (Feldman, Prostko, 2002).
Прайминг. Как и при изучении понимания, при исследовании порождения активно используется метод прайминга. Предполагается, что предварительное предъявление прайма с тем же корнем, что и целевой стимул, поможет испытуемому быстрее дать ответ при наличии морфологического уровня в МЛ.
Классической в этой области считается разработанная А. Мейер (Meyer, 1990) методика онлайновой подготовки (англ, on-line preparation), или методика имплицитного прайминга (англ, implicit priming). Задача испытуемого состоит в том, чтобы, заучив некоторый набор пар слов-подсказок (англ, prompts) и слов-ответов (англ, responses), как можно быстрее назвать слово- ответ при предъявлении слова-подсказки; экспериментатор же замеряет время от появления слова-подсказки до начала произнесения слова-ответа. При этом экспериментальная серия составлена из блоков двух типов: в одних блоках все слова-ответы содержат общую часть (например, один и тот же первый звук или слог), а в остальных — слова-ответы не похожи друг на друга. Предполагается, что при условии однородности целевых стимулов по сравнению с условием их неоднородности должен проявиться положительный прай- минг-эффект за счет того, что испытуемый уже успел «подготовиться» к произнесению определенного речевого отрезка. Если общий начальный сегмент целевых стимулов составляет целую морфему (приставку или корень), то в экспериментах с онлайновой подготовкой можно ожидать большего прайминга по сравнению с условием, когда первый слог меньше морфемы, если в МЛ есть морфемное представление слова.
Вариантом имплицитного прайминга является задание на ассоциацию стимула и местоположения (англ, position-response association task), при котором вместо слов-подсказок используются местоположения на экране иконки с изображением громкоговорителя (Bien et al., 2005,2011). В отличие от предыдущей методики на этапе заучивания пар слова-ответы предъявляются испытуемому только в устной модальности, что позволяет избежать влияния орфографии.
Наряду с имплицитным праймингом используется также методика интерференции слов и картинок (англ, picture — word interference). Испытуемому попеременно показывают картинки и слова-дистракторы (англ, distractors). Когда человек видит перед собой картинку, то ему нужно назвать то, что на ней изображено. Дистракторы же его просят либо игнорировать, либо читать вслух. Дистрактор, предъявляемый непосредственно перед стимульной картинкой, может служить праймом, как ускоряющим называние картинки в случае фонетического сходства или ассоциативной связи между двумя словами, так и замедляющим этот процесс в случае категориальной связи между ними (Bölte et al., 2004). Данная методика воспроизводит морфологический прайминг с отложенным предъявлением стимула для порождения, однако ее применимость ограничена той предметной лексикой, для которой можно подобрать легко и однозначно описываемую картинку.
Аналогом прайминга корнем в задачах на понимание является прайминг при асинхронии предъявления стимула (англ, stimulus onset asynchrony priming task) (Schreuder, 1990; Schreuder et al., 1990), когда стимул может появиться в двух условиях: сразу целиком, либо сначала появляется только его начало или конец. Во втором случае предполагается, что предварительное предъявление морфемы, содержащейся в целевом стимуле, ускорит процесс называния, если в МЛ есть репрезентации отдельных морфем.
Образование дериватов. В 70-80-е годы популярной была методика, при которой испытуемый образовывал от предъявляемого ему слова-основы новые слова по определенной модели (англ, word creation paradigm) (Steinberg, 1973, цит. no MacKay, 1978) или называл существующий дериват определенного типа, например отглагольное существительное от основы глагола (MacKay, 1978). Предполагалось, что если деривационная гипотеза верна, то количество правил, применяемых для образования производных слов, будет определять время ответа и влиять на количество ошибок. Однако при исследовании словообразования эта методика не получила широкого распространения.
Порождение письменного текста. Наряду с порождением устного текста можно изучать потенциальное влияние морфемной организации МЛ на порождение письменного текста. В частности, интерес представляет сравнение временных интервалов между нажатиями двух клавиш клавиатуры на границе морфем и внутри морфем (Sahel et al., 2008; Will et al., 2006). Если человек планирует свой будущий письменный текст поморфемно, то между этими условиями должна проявиться разница.
Интерактивные методики. Недавно также появилась интерактивная методика, названная ее создателями (Libben, Weber, 2012) техникой РЗ (англ. РЗ technique), которая позволяет проводить эксперимент одновременно на паре испытуемых. Задача первого испытуемого состоит в том, чтобы как можно быстрее озвучить слово, подвергнутое постепенной демаскировке; услышав его ответ, второй испытуемый должен как можно быстрее напечатать целевое слово. Таким образом, экспериментатор может одновременно получить данные как по порождению устного и письменного текста, так и по пониманию, привнося в эксперимент коммуникативную составляющую.
Морфологические эффекты, наблюдаемые с помощью поведенческих методов
В этой главе мы представим некоторые факты, касающиеся морфологии в МЛ, которые были получены в поведенческих экспериментах и должны учитываться при выборе оптимальной архитектуры МЛ. Сначала будут рассмотрены эмпирические данные, затрагивающие вопрос о сходстве и различии словоизменения и словообразования. Затем будут изложены потенциальные проблемы, связанные с кодированием отношений между морфемами в рамках одного слова при условии их хранения в МЛ. Следующая часть этой главы будет посвящена вопросам репрезентации корней в МЛ и особенностям их участия в обработке слова. В заключительной части мы обратимся к роли частотности в опознании слов и ее связи с морфемной организацией МЛ. Мы намеренно оставили в стороне вопрос о различии в репрезентации регулярных и нерегулярных форм слова, так как он гораздо шире освящен в русскоязычной литературе, чем другие аспекты, связанные с представлением морфологии в МЛ, см., например, обзоры в работах Свистуновой (2008), Черниговской и др. (2009).
Словоизменение и словообразование
С точки зрения теоретической лингвистики, словоизменение и словообразование являются разными процессами. Однако данные поведенческих экспериментов на разном языковом материале как подтверждают их различие, так и не опровергают их сходство. Хотя этот факт может быть связан с тем, что не все методики одинаково чувствительны к такому тонкому противопоставлению, тем не менее, подобного рода данные могут свидетельствовать о сходстве механизмов обработки и хранения словоизменительных и словообразовательных показателей.
Так, на английском материале при прайминге с отложенным предъявлением стимула словоформы одной лексемы по отношению друг к другу являлись более успешными праймами, чем однокоренные слова (Fowler et al., 1985), хотя в аналогичном более позднем исследовании таких различий не было обнаружено (Raveh, Rueckl, 2000). При прайминге с непосредственным предъявлением стимула различие между словоизменением и словообразованием было получено только при большей асинхронии времени предъявления стимула (Raveh, 2002).
На немецком материале при прайминге с отложенным предъявлением стимула был получен частичный прайминг между словоформами одной лексемы для прилагательных и отсутствие прайминга между дериватами, образованными от основ тех же прилагательных (Schriefers et al., 1992), но в экспериментах с интерференцией слов и картинок морфологический прайминг равного размера был получен как при непосредственном предъявлении стимула, так и при интервале в 7-10 филлеров независимо от типа связи между праймом и целевым словом (словоизменительная / словообразовательная) (Zwitserlood et al., 2000).
На испанском материале при неосознаваемом прайминге с маскировкой однокоренные слова и словоформы одной лексемы были одинаково успешными праймами, но при осознаваемом прайминге с непосредственным предъявлением стимула словообразовательные дериваты не оказывали никакого влияния (Sänchez-Casas et al., 2003).
Далее, не было получено различия между словоизменением и словообразованием для иврита в экспериментах с праймингом при отложенном предъявлении стимула (Feldman, Bentin, 1994), что привело авторов исследования к гипотезе о кластерной организации МЛ для иврита. Тем не менее, эти данные не следует напрямую соотносить с данными по европейским языкам, так как в иврите, как семитском языке, морфологические процессы не являются линейными: корень представлен 3-4 согласными и не употребляется сам по себе, а словообразовательные и словоизменительные показатели соответствуют гласным, которые «вставляются» между согласными корня.
Для финского языка в задаче лексического решения первая и вторая фиксации взгляда на непроизводных существительных в косвенном падеже занимают значительно больше времени по сравнению с суффиксальными существительными в номинативе (Hyönä et al., 1995). По мнению исследователей, это говорит в пользу модели SAID, в которой словообразовательные дериваты обрабатываются цельнословно, а слова со словоизменительными показателями требуют морфологической декомпозиции. Однако открытым остается вопрос о том, действительно ли являются полученные различия следствием разных механизмов хранения и обработки, а не эффектом контекста: на фоне существительных в именительном падеже независимо от их морфемного строения и частотности существительные в косвенном падеже в принципе могут восприниматься как более «аномальные» и, соответственно, требовать больше времени на принятие решения.
Отношения между морфемами
В данном разделе будут рассмотрены эффекты, связанные с отношениями между несколькими морфемами в рамках одного слова, которые предполагают хранение отдельных морфем в МЛ.
Перестановка букв. По данным, полученным на материале английского (Christianson et al., 2005), испанского и баскского (Dunabeitia et al., 2007) языков, положительный прайминг наблюдается, только если буквы в прайме переставлены внутри одной морфемы, но не на их границе. Следовательно, перестановка букв на морфемной границе должна прерывать опознание слова и быть аргументом в пользу морфемного анализа. Однако в повторном исследовании на английском языке (Rueckl, Rimzhim, 2011) оказывал воздействие и прайм с переставленными на морфемной границе буквами, что противоречит полученным ранее результатам и, скорее, свидетельствует в пользу холистической стратегии обработки.
При добавлении дополнительного фактора — семантической близости — оказывается, что только настоящие дериваты с переставленными буквами на морфемной границе в отличие от псевдоаффиксаль- ных являются эффективными праймами для мономор- фемного слова (Diependaele et al., 2013).
Кроме того, хорошим праймом является псевдослово, составленное из существующих морфем, но не псевдослово с переставленными буквами внутри корня (Beyersmann et al., 2012) и на границе корня и суффикса (Diependaele et al., 2013), что должно объясняться невозможностью цельной обработки для псевдослов в отличие от слов.
По мнению X. Дуньябейтья и коллег (Dunabeitia et al., 2014), непоследовательность в наблюдаемых эффектах от переставленных букв на границе и внутри корня является следствием того, что быстро читающие и медленно читающие люди могут пользоваться различными стратегиями. Так, в их экспериментах более быстрым испытуемым прайм с переставленными в корне буквами лучше помогал опознать целевое слово по сравнению с праймом, в котором переставленные буквы были заменены на другие, сходные по частотности; прайм с переставленными на морфемной границе буквами оказывал такое же воздействие, что и прайм с замененными буквами на месте морфемной границы. Для медленных же испытуемых оба типа праймов с переставленными буквами были более эффективными, чем праймы с замененными буквами, так как они, вероятно, меньше опирались на графическую информацию о слове и были менее чувствительны к «шуму» в поступающем потоке информации, в отличие от быстрых читателей. Поэтому удачная модель МЛ, вероятно, должна допускать в сигнале некоторое количество помех, которые не будут мешать успешной обработке информации.
Порядок присоединения аффиксов. Обычно порядок присоединения морфем к корню легко установить, в частности, сначала присоединяются словообразовательные, а затем словоизменительные показатели. Однако в некоторых случаях возможны варианты присоединения аффиксов, соответствующие разным значениям, например английское прилагательное unlockable может соотноситься с тем, что нельзя закрыть, при правом ветвлении (ип-lockable), или с тем, что можно быть открыто, при левом ветвлении (unlock-able). Эти теоретические различия в порядке присоединения аффиксов должны отражаться в стратегиях, которые люди используют при чтении. В задаче лексического решения при принудительной сегментации с помощью дефисов на границе корня и приставки или корня и суффикса такие неоднозначные слова опознавались с одинаковой скоростью, хотя аналогичные однозначные прилагательные независимо от типа ветвления быстрее опознавались при выделении приставки (Libben, 2003). При изучении обработки таких омонимичных прилагательных в контексте с помощью регистрации движений глаз было показано, что предшествующий контекст, который мог указывать на одно из значений или оставаться нейтральным, не влияет на их опознание (Pollatsek et al., 2010). Более того, для испытуемых предпочтительной оказывалась интерпретация, соответствующая левому ветвлению (unlock-able), что авторы статьи объясняют большей частотностью слов модели ипХ по сравнению с Xable.
Если в процессах, связанных с пониманием, порядок декомпозиции может варьироваться, как было показано выше, то для процессов порождения предполагается последовательное планирование морфем. Это подтверждается в экспериментах с онлайновой подготовкой на материале нидерландского и немецкого языков (Roelofs, 1996; Janssen et al., 2004): если общий первый слог целевых стимулов составляет целую морфему (приставку или корень), наблюдается больший прайминг по сравнению с условием, когда первый слог меньше морфемы; кроме того, общие неначальные морфемы целевых слов никак не помогают испытуемому, как и общие неначальные слоги (Меуег, 1990; 1991).
Линейное взаиморасположение морфем. В лингвистике аффиксы делятся на суффиксы и приставки, исходя из их линейного расположения относительно корня, однако неясно, принимается ли в расчет это позиционное различие при морфемном анализе.
Аффиксы. Некоторым свидетельством в пользу этого можно считать результаты, полученные в исследовании Д. Крепальди и коллег (Crepaldi et al., 2010): если псевдослова из существующего корня и существующего суффикса (например, англ, gasful) опознаются в задаче лексического решения медленнее псевдослова из существующего корня и несуществующего суффикса (например, англ, gasfll), то при перестановке местами корня и суффикса этот эффект исчезает. Кроме того, не различается время реакции на псевдослова, полученные перестановкой местами корня и суффикса в существующем слове, и псевдослова, в котором до корня располагается псевдоприставка. Таким образом, при опознании суффиксы опознаются как суффиксы только на своем месте.
Сложные слова. В отличие от аффиксов корень может занимать как начальную позицию в слове, так и следовать за приставкой или другим корнем, а значит, на его опознание не должны накладываться ограничения, связанные с местоположением. Так как в сложных словах корни могут занимать как начальную, так и конечную позицию, то если морфемная декомпозиция осуществляется, можно ожидать замедление времени реакции на псевдослова, полученные перестановкой корней в сложном слове (например, moonhoney из honeymoon ‘медовый месяц’), по сравнению с несуществующими сложными словами (например, moonbasin от moon ‘луна’ basin ‘резервуар’) за счет интерференции с существующим сложным словом. Эта гипотеза подтвердилась в эксперименте (Crepaldi et al., 2013). Более того, сложное слово с переставленными корнями служит эффективным праймом для того же сложного слова в правильном написании, что свидетельствует об активации корней в таких псевдословах.
Экспериментальные данные, касающиеся позиционного кодирования аффиксов относительно корня и корней в сложном слове, пока нашли слабое отражение в теоретических моделях и нуждаются в дальнейшем объяснении. Кроме того, данный феномен нуждается в изучении на материале языков, в которых отсутствуют приставки, например уральских или алтайских.
Категориальная сочетаемость аффиксов. Важным аргументом против супралексического подхода выступают данные, говорящие о морфемном анализе псевдослов с выраженной морфемной структурой. Так, в задаче лексического решения испытуемым сложнее отвергнуть незафиксированную в языке последовательность приставки и корня по сравнению с псевдословом из существующей приставки и несуществующего корня (Taft, Forster, 1975), незафиксированную в языке последовательность корня и суффикса по сравнению с псевдословом из существующего корня и несуществующего суффикса, несуществующего корня и существующего суффикса и псевдословом без морфемной структуры (Caramazza et al., 1988; Burani et al., 2002; Ferrari, Kacinik, 2014). Более того, при назывании на псевдослова с морфемной структурой тратится меньше времени, чем на другие псевдослова (Burani et al., 1999; Burani et al., 2002). Исследования псевдослов с морфемной структурой важны также и потому, что при восприятии незнакомых слов, существующих в языке, должны быть задействованы сходные механизмы.
Однако не все сочетания морфем между собой возможны в языке: некоторые аффиксы накладывают определенные ограничения на тип присоединяемой основы. В частности, согласно результатам, полученным на материале греческого языка (Manouilidou, 2007), предполагается, что существует определенная шкала приемлемости неслова, на одном полюсе которой располагаются потенциально возможные в языке сочетания, а на другом конце шкалы — неслова, состоящие из несуществующего корня и существующего афффикса. Между ними же располагаются псевдослова, нарушающие валентностные и категориальные ограничения. В задаче лексического решения время реакции на такие псевдослова соотносилось с их положением на шкале приемлемости.
Другой аспект, который может определять обработку псевдослова, — его семантическая интерпретируемость. В задаче лексического решения на то, чтобы отвергнуть псевдослова, которые легко проинтерпретировать, требуется больше времени (Burani et al., 1999). При кроссмодальном прайминге псевдослова, которые невозможно проинтерпретировать, не являются успешными праймами в отличие от легко интерпретируемых псевдослов (Feldman, Bentin, 1994; Meunier, Longtin, 2007).
Семантическая прозрачность. Сопоставление слов с (не)композициональным сочетанием морфем началось с исследования У Марслен-Уилсона с коллегами (Marslen-Wilson et al., 1994), в котором с помощью методики кроссмодального прайминга было показано, что только семантически прозрачные дериваты являются хорошими праймами по отношению друг к другу, а значит семантически непрозрачные комплексы морфем должны храниться и обрабатываться целиком. Однако данное обобщение было поставлено под сомнение в дальнейших исследованиях.
Суффиксальные дериваты. Во многих последующих исследованиях различие между семантически прозрачными и непрозрачными словами не было подтверждено на английском (Rastle et al., 2000; Marlsen- Wilson et al., 2008), французском (Longtin et al., 2003), испанском (Sänchez-Casas et al., 2003) и русском (Kaza- nina et al., 2008) материалах в экспериментах с неосознаваемым праймингом.
Различия между этими двумя типами слов проявились на английском материале при кроссмодальном прайминге при любой асинхронии и только при большей асинхронии между предъявлениями прайма и стимула в письменной модальности (Feldman et al., 2004). При большой асинхронии также проявляется в объеме положительного воздействия влияние размера семьи, определяющейся по количеству семантически прозрачных членов. Методика прайминга при записи движений глаз в экспериментах с английским языком также выявила уменьшение длительности фиксаций на целевом слове при прайминге семантически прозрачным однокоренным словом, но не семантически непрозрачным (Patterson et al., 2011).
Кроме того, в экспериментах с обратной маскировкой на материале французских суффиксальных дериватов (Diependaele et al., 2005) семантически непрозрачные праймы оказывали положительное воздействие на целевые стимулы, но в меньшей степени, чем семантически прозрачные дериваты. Особенно ярко это различие проявилось при предъявлении стимулов в письменной модальности, а не в устной. Хотя этот факт, по мнению авторов, и свидетельствует о цельнословном хранении слов с некомпозициональной семантикой, такие слова, с их точки зрения, при опознании должны как подвергаться морфемному анализу, так и параллельно обрабатываться целиком. Аналогично, в работе Л. Фельдмана и коллег (Feldman et al., 2009) было получено различие в объеме воздействия на французском материале и при обычном неосознаваемом прайминге в письменной модальности.
Приставочные дериваты. Эксперименты на немецком материале дают противоречивые свидетельства. Так по данным Heide (2010) в задаче лексического решения испытуемые отвечали быстрее и совершали меньше ошибок в случае семантически прозрачных глаголов (например, verschieben ‘отодвинуть’ от schieben ‘двигать’) по сравнению с семантически непрозрачными глаголами (например, vertragen ‘терпеть’ от tragen ‘нести’). Автор статьи объясняет полученное расхождение за счет разного хранения слов в ментальном лексиконе: для глаголов первого типа — поморфемное хранение, а для глаголов второго типа — цельнословное. При этом предполагается обязательная декомпозиция для обоих типов слов: в первом случае она приведет к успешному доступу к ментальному лексикону, а во втором — к повторному анализу слова и цельнословному анализу (из-за этого реанализа скорость обработки меньше и возникает больше ошибок). Однако результаты экспериментов с осознаваемым праймин- гом в разных модальностях говорят, скорее, о декомпозиции независимо от семантических отношений между морфемами (Smolka et al., 2014). Е. Смолка с коллегами элегантно обходит проблему композициональности семантики, постулируя хранение концептов для многоморфемных основ, что, возможно, является наиболее удачным решением по сравнению с остальными.
Имлицитный прайминг приставкой для нидерландских слов с семантически прозрачной и непрозрачной структурой практически не отличается по величине, что говорит о декомпозиции (Roelofs, Ваауегп, 2002).
Сложные слова. Результаты экспериментов со сложными словами свидетельствуют в пользу помор- фемного хранения. Так, в работе П. Домес (Dohmes et al., 2004) на немецком материале при прайминге непроизводного слова (например, Ente ‘утка’) двумя типами сложных слов: семантически прозрачных (типа нем. Wildente ‘дикая утка’, ср. wild ‘дикий’ и Ente ‘утка’) и с некомпозициональной семантикой (типа нем. Zeitungsente ‘газетная утка’, ср. Zeitung‘газета’ и Ente ‘утка’) наблюдалось положительное воздействие одинаковой величины. При этом получаемый эффект нельзя объяснить простым сходством по форме: при прайминге сходными по форме, но не родственными словами ускорения не наблюдается (то есть, например, хорошим праймом к нем. Rose ‘роза’ будет Buschrose ‘кустовая роза’, но не Neurose ‘невроз’, хотя во всех трех словах содержится сегмент rose). Аналогично, на финском материале (Pollatsek, Hyöna, 2005) паттерны движений глаз не различались в случае семантически прозрачных и непрозрачных сложных слов.
Основной проблемой исследований, посвященных некомпозициональной семантике морфемных комплексов, остается тот факт, что решение о семантической непрозрачности слова зачастую основывается на интуиции экспериментатора. Если в случае сложных слов некомпозициональность значения относительно легко определить, так как значение отдельных корней можно взять из толкований мономорфемных слов в словаре, то в случае суффиксов и приставок экспериментаторы не располагают подобными источниками и обычно опираются не собственно на критерий композицональности, а на степень близости значения корня значению его деривата. Кроме того, при оборе стимульного материала обычно не проводится четкой границы между семантически непрозрачными суффиксальными словами и псевдосуффиксальными.
Особенности корня
В этом разделе будут рассмотрены исследования, направленные на изучение репрезентации корня в МЛ и особенностей, связанных с его обработкой.
Связанные корни. Связанными в лингвистике называют корни, которые встречаются в словах только в сочетании с другими словообразовательными морфемами (например, mit в английских словах submit ‘подчиниться’ и permit ‘позволить’), те же корни, что могут употребляться самостоятельно, — свободные. Соответственно, представленность в МЛ связанных корней по сравнению со свободными теоретически является менее вероятной, однако экспериментальные данные, скорее, свидетельствуют об обратном. Хотя на английском материале в экспериментах с кроссмо- дальным морфологическим праймингом не было обнаружено ускорения времени реакции на целевое слово в парах, где прайм и стимул содержат общий связанный корень в отличие от слов со свободными корнями (Marslen-Wilson et al., 1994), в аналогичных экспериментах (Forster, Azuma, 2000) в письменной модальности был получен прайминг между словами со связанными корнями той же величины, что и между словами со свободными корнями (Forster, Azuma, 2000; Pastizzo, Feldman, 2004). В прайминг-экспериментах с польским языком ускоряют опознание целевого стимула только те корни, которые сами по себе образуют слово, а в аналогичных экспериментах с греческим языком корень служит эффективным праймом, хотя не может употребляться самостоятельно (Kehayia, Jarema, 1994), что также верно и для финских алломорфов корня (Jär- vikivi, Niemi, 2002).
Корни с чередованиями. Как при словообразовании, так и при словоизменении в корне могут возникать чередования. Соответственно, в МЛ могут храниться все возможные алломорфы корня или одна репрезентация с недоспецифицированными признаками. В литературе вторая точка зрения является более популярной, что поддерживается тем же объемом морфологического прайминга между словами с чередованиями в корне, что и между словами без чередований в корне на валлийском (Воусе et al., 1987), сербохорватском (Feldman, Fowler, 1987), польском (Reid, Marslen-Wilson, 2000), финском (Järvikivi, Niemi, 2002), немецком (Smolka et al., 2007) и английском материале (McCormick et al., 2008). Однако в экспериментах с родственным польскому болгарским языком, если в корне прайма нет беглого гласного, а в целевом стимуле он есть, прайминг-эффект оказывался меньше, чем в том случае, когда корень у прайма и стимула выглядит одинаково (Bertinetto, Jetchev, 2005). Авторы статьи используют этот факт в качестве аргумента в пользу цельнословного хранения слов с чередованием.
Перестановка букв в корне. Как уже было сказано выше, перестановка букв внутри морфемы не мешает активации исходного слова (англ, oeby из obey ‘подчиняться’), однако данный эффект не наблюдается, если речь идет о переставленных двух первых буквах корня в начале слова — boey (Rayner et al., 2006; White et al., 2008), что связывают с особой перцептивной выделенностью начала слова. Однако если двум первым переставленным в корне буквам предшествует приставка, независимо от того существует ли слово, состоящее из этой приставки и корня (disboey из disobey ‘не слушаться’ vs. reboey из reobey), этот эффект возвращается (Taft, Nillsen, 2012), что поддерживает гипотезу о морфемном анализе при опознании, происходящем одновременно с анализом двубуквенных сочетаний.
Корень vs. БОСС. Роль корня в опознании неоднократно оспаривалась М. Тафтом, предлагавшем альтернативную единицу, релевантную для получения доступа к МЛ, — БОСС (Taft, 1979а; 1987; Rouibah, Taft, 2001). Аргументом в пользу существования этих единиц использовалось более быстрое опознание слова в условиях, когда БОСС перцептивно выделен в слове. Однако в заданиях с иллюзорными связываниями испытуемые, скорее, были склонны сохранять целостность слога, нежели БОСС (Seidenberg, 1987), а использование БОСС в качестве прайма дает одинаковое по объему воздействие со слогами (Lima, Pollatsek, 1983).
Частотность
Важность роли частотности при опознании слова подчеркивалась, начиная с модели лексического поиска К. Форстера (Forster, 1976). Однако с течением времени и развитием корпусных технологий происходит постепенное осознание того факта, что на обработку слова, по-видимому, влияют не столько высокая или низкая встречаемость собственно слова или составляющих его морфем, сколько принадлежность слова к определенной морфологической семье, а также к определенным моделям словоизменения и словообразования. Поэтому сначала мы поговорим о традиционной абсолютной частотности, а затем остановимся подробнее на более сложных мерах, вычисляемых на ее основе, которые разрабатываются в рамках теории информации.
Поверхностная частотность vs. лексемная частотность. Поверхностной частотностью (англ, surfacefrequency) в западной литературе принято называть частотность отдельной словоформы в противовес лексемной частотности (также ее иногда называют частотностью основы), которая вычисляется как суммарная частотность всех словоформ данной лексемы. Влияние поверхностной частотности на скорость опознания слова принято считать аргументом в пользу хранения целых словоформ в МЛ, влияние же лексемной частотности поддерживает гипотезу о репрезентации основы в МЛ. Эти эффекты были засвидетельствованы на материале английского (Taft, 1979b), французского (Cole et al., 1989), нидерландского (Baayern, 1997), немецкого (Schreuder, Baayen, 1997) языков в задаче лексического решения. Дополнительным свидетельством важной роли частотности слова для его опознания являлся бы различный объем воздействия при морфологическом прайминге, однако эксперименты в этой области дают противоречивые результаты: больший прайминг-эффект для частотных слов (Giraudo, Grainger, 2000), меньший прайминг-эффект для частотных слов (Meunier, Segui, 1999), прайминг равного объема (McCormick et al., 2008).
Частотность отдельных аффиксов. Влияние частотности отдельных аффиксов на обработку целого слова связывают с наличием / отсутствием репрезентаций отдельных морфем в МЛ, а также с возможностью морфемного анализа при опознании. Подтверждения этого факта для отдельных морфем были получены для аффиксов (Taft, 1979а; Laudanna et al., 1994), а также для корней в сложных словах (Kuperman et al., 2008; Kuperman et al., 2009).
Частотность корня и эффект размера семьи. Размер семьи определяется как количество словообразовательных дериватов данного корня, а частотность корня (семьи) равна сумме лексемных частотностей его дериватов. По экспериментальным данным, размер семьи значимо влияет на обработку в том числе и мономорфем- ного слова в задаче лексического решения (Baayen et al., 2006; Juhasz, Berkowitz, 2011) и при записи движений глаз (Kuperman et al., 2010; Juhasz, Berkowitz, 2011): чем больше семья, тем быстрее опознается слово. При этом при постепенной демаскировке в отличие от лексического решения значимым является влияние поверхностной частотности, но не размера семьи (Schreuder, Baayen, 1997), а значит, эти два параметра вступают в действие в разное время: поверхностная частотность — на более ранних стадиях обработки, а размер семьи — на более поздних этапах, что говорит о его семантической природе, а именно, на пост-лексическом этапе обработки
активируются все однокоренные слова данного стимула. Кроме того, слово, относящееся к семье, в которой большинство членов высокочастотны, опознается быстрее слова, относящегося к семье, в которой мало частотных представителей (Moscoso del Prado Martin et al., 2004). По-видимому, в высокочастотной семье связи между однокоренными словами и их корнем являются более прочными, что обеспечивает более эффективную обработку слов с такими корнями.
Информационный подход. Несмотря на подтвержденные значимые эффекты частотности словоформы, лексемы и семьи, более успешными предикторами времени реакции в задаче лексического решения и паттернов движений глаз при чтении оказываются меры, учитывающие не только частотность единицы МЛ как таковой, но и соотношение этой частотности с частотностями других единиц и частотностями определенных словоизменительных и словообразовательных моделей, а также количество передаваемой ею информации. Такими мерами являются словообразовательная энтропия (англ, derivational entropy), словоизменительная энтропия (англ, inflectional entropy), а также количество информации, передаваемое конкретной словоформой.
Количество информации, передаваемое конкретной словоформой, вычисляется по формуле (3), где т соответствует конкретной словоформе, Fm — частотность словоформы m,Rm — количество значений / функций данной словоформы, М — количество различных словоформ данной лексемы. Эта мера отражает семантическую нагруженность конкретной словоформы по отношению к другим словоформам данной лексемы и предопределяет скорость ее обработки (Kostic, Mirkovic, 2002; Kostic, Havelka, 2002; Seva, Kostic, 2003).
Словоизменительная энтропия для конкретного слова вычисляется исходя из частотности его словоформ по формуле (1), гдe/(w) соответствует лексемной частотности слова w, a f(Wj) — частотности конкретной словоформы Wj (Milin et al., 2009). При этом различными Wj считаются только те словоформы, которые выглядят различно. Иначе говоря, при подсчете словоизменительной энтропии слово кошке, которое может являться как словоформой дательного, так и предложного падежа, будет считаться как одна w„ а ftw} будет соответствовать кумулятивной частотности ее употреблений как дательного, так и предложного падежей.
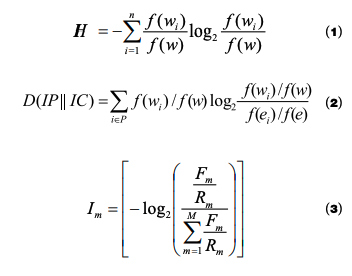
Кроме того, при изучении словоизменения учитывается также относительная энтропия между распределением словоизменительной парадигмы и распределением словоизменительного класса, вычисляемая по формуле (2), где flw) соответствует лексемной частотности слова w, f(Wj) — частотности конкретной словоформы f(e) — суммарная частотность всех словоформ в той же форме, что и wit относящихся к тому же словоизмени- телному классу, что и данная лексема, a f(e) — суммарная частотность всех словоформ всех лексем, относящихся к данному словоизменительному классу. На опознание конкретного слова влияют как распределение словоформ в рамках парадигмы данной лексемы (что отражено количественно в словоизменительной энтропии), так и распределение словоформ с данным показателем в рамках данного словоизменительного класса. Если эти два распределения различаются между собой, обработка слова оказывается затрудненной (Milin et al., 2009).
Словообразовательная энтропия вычисляется аналогично словоизменительной, только исходя из частотностей лексем, содержащих данный корень. Ее влияние на опознание также было зафиксировано в ряде работ (Moscoso del Prado Martin et al., 2004; Baayen et al., 2006). Влияние таких мер, как словоизменительная и словообразовательная энтропия, на опознание слова предполагает парадигматическую организацию хранения слов в МЛ, что по сути возвращает нас к архитектуре МЛ, напоминающей сетевую модель Дж. Байби (Bybee, 1985; 1995) и пока находит слабое отражение в современных моделях гибридного типа.
Заключение
На настоящий момент не существует общепринятой точки зрения ни на то, каким образом организовано хранение языковых единиц в МЛ, ни на то, как происходит обработка языковых единиц при зрительном восприятии. Кроме того, модели, строящиеся для объяснения понимания, могут слабо соотноситься с моделями, призванными объяснить процессы при порождении речи. Тем не менее можно выделить некоторые тенденции в современных подходах к морфологии в МЛ, а именно: сосуществование двух путей доступа (поморфемного и цельнословного), хранение репрезентаций отдельных морфем, наличие уровня единиц, промежуточных между фонологическим / графическим и семантическим / концептуальным представлениями.
Если сначала многие предположения формулировались на материале английского языка и при этом претендовали на универсальность, то сейчас все больше говорят об индивидуальной специфичности каждого языка и невозможности построить такую архитектуру МЛ, которая подходила бы под данные любого языка. Однако на данный момент большинство исследований, посвященных морфологии, проводится на материале европейских языков, таких как английский, немецкий, нидерландский, французский, итальянский, испанский, сербский. Если говорить об исследованиях русского МЛ, то больше внимания уделяется глагольному словоизменению по сравнению с именным, словоизменению по сравнению со словообразованием.
Для изучения роли морфологии в МЛ психолингвисты и экспериментальные психологи разработали множество методов, среди которых поведенческие являются по-прежнему востребованными и актуальными. Поведенческие методики позволяют изучать процессы обработки слов при понимании и порождении с учетом различных факторов, связанных с морфемной структурой: таких как частотные характеристики морфологически релевантных единиц (морфем, словоформ), степень семантической прозрачности морфемного комплекса, словоизменение / словообразование и т.д. Важным этапом в изучении морфологии в МЛ выступает создание вспомогательных средств: доступных и обширных баз данных, аккумулирующих информацию о частотности словоформы и лексемы, количестве соседей для конкретного слова, размере и частотности морфологической семьи, к которой принадлежит данное слово, а также программ автоматического создания псевдослов; для некоторых европейских языков шаги в этом направлении уже были сделаны (см., например, базы данных CELEX для английского, нидерландского и немецкого языков (Ваауеп et al., 1995) и Lexique для французского языка (New et al., 2001), программу Wuggy (Keuleers & Brysbaert, 2010), работающую с английским, баскским, немецким, нидерландским, французским и сербским языками).
Возможным направлением дальнейшего развития этой области видится охват большего количества языков разных языковых семей, уделение большего внимания индивидуальным различиям, а также создание и апробация моделей, которые будут фокусироваться в равной степени как на порождении, так и на понимании речи в различных модальностях.
Литература
Allen, M., & Badecker, W. (2002). Inflectional regularity: Probing the nature of lexical representation in a cross-modal priming task. Journal of Memory and Language, 46(4), 705-722. doi: 10.1006/jmla.2001.2831
Allen, M., & Badecker, W. (2002). Stem homographs and lemma level representations. Brain and Language, 81(1), 79-88. doi: 10.1006/brln.2001.2508
Baayen, R., Piepenbrock, R., 8r Gulikers, L. (1995). The CELEX lexical database (CD-ROM). Philadelphia, PA: Linguistic Data Consortium, University of Pennsylvania.
Baayen, R.H. (2014). Experimental and psycholinguistic approaches to studying derivation. In R. Lieber, & P. Stekauer (Eds.), Handbook of derivational morphology (pp. 95-117). Oxford: Oxford University Press.
Baayen, R.H., Dijkstra, T, 8r Schreuder, R. (1997). Singulars and plurals in Dutch: Evidence for a parallel dual-route model. Journal of Memory and Language, 37(1), 94-117. doi: 10.1006/jmla. 1997.2509
Baayen, R.H., Feldman, L. B., 8r Schreuder, R. (2006). Morphological influences on the recognition of monosyllabic mono- morphemic words. Journal of Memory and Language, 55(2), 290-313. doi: 10.1016/j.jml.2006.03.008
Badecker, W., 8r Allen, M. (2002). Morphological parsing and the perception of lexical identity: A masked priming study of stem homographs. Journal of Memory and Language, 47(1), 125-144. doi: 10.1006/imla.2001.2838
Bentin, S., 8r Feldman, L. B. (1990). The contribution of morphological and semantic relatedness to repetition priming at short and long lags: Evidence from Hebrew. The Quarterly Journal of Experimental Psychology, 42(4), 693-711. doi: 10.1080/14640749008401245
Bertinetto, P.M., 8r Jetchev, G. (2005). Lexical access in Bulgarian: nouns and adjectives with and without floating vowels. Catalan Journal of Linguistics, 4,171-198.
Bertram, R., Kuperman, V., Baayen, R.H., 8r Hyönä, J. (2011). The hyphen as a segmentation cue in triconstituent compound processing: It's getting better all the time. Scandinavian journal of psychology, 52(6), 530-544. doi: 10.1 lll/i.1467-9450.2011.00914.x
Beyersmann, E., Dunabeitia, J. A., Carreiras, M., Coltheart, M., 8r Castles, A. (2013). Early morphological decomposition of suffixed words: Masked priming evidence with trans- posed-letter nonword primes. Applied Psycholinguistics, 34(05), 869-892. doi: 10.1017/80142716412000057
Bien, FL, Baayen, R.H., 8r Levelt, W.J. (2011). Frequency effects in the production of Dutch deverbal adjectives and inflected verbs. Language and Cognitive Processes, 26(4-6), 683-715. doi: 10.1080/01690965.2010,511475
Bien, FL, Levelt, W.J., 8r Baayen, R.H. (2005). Frequency effects in compound production. Proceedings of the National Academy of Sciences of the United States of America, 102(49), 17876-17881. doi: 10.1080/01690965.2010,511475
Bölte, J., Zwitserlood, P., 8r Dohmes, P. (2004). Morphology in experimental speech production research. In T. Pech- mann, 8r C. Habel (Eds.), Multidisciplinary Approaches to Language Production (pp. 431-472). Berlin: Mouton de Gruyter.
Boyce, S.,Browman, C.,8rGoldstein, L.(1987).Lexicalorganization and Welsh consonant mutations. Journal of Memory and Language, 26(4), 419-452. doi: 10.1016/0749-596X(87)90100-8
Bradley, D. (1980). Lexical representation of derivational relation. In M. Aronofif, 8r M.-L. Kean (Eds.), Juncture (pp. 37-55). Saratoga, CA: Anma Libri.
Burani, C., Dovetto, F.M., Spuntarelli, A., 8r Thornton, A. M. (1999). Morpholexical access and naming: The semantic interpretability of new root-suffix combinations. Brain andLanguage, 68(1-2), 333-339. doi: 10.1006/brln.l999.2073
Burani, C., Marcolini, S., & Stella, G. (2002). How early does morpholexical reading develop in readers of a shallow orthography? Brain and Language, 81(1), 568-586. doi: 10.1006/ brln.2001.2548
Butterworth, B. (1983). Lexical representation. In Language production. Vol. 2. Development, Writing and Other Language processes (pp. 257-294). London: Academic Press.
Bybee, J.L. (1985). Morphology: A study of the relation between meaning and form. Philadelphia, PA: John Benjamins Publishing. doi: 10.1075/tsl.9
Bybee, J.L. (1995). Regular morphology and the lexicon. Language and Cognitive Processes, 10(5), 425-455. doi: 10.1080/01690969508407111
Caramazza, A., Laudanna, A., & Romani, C. (1988). Lexical access and inflectional morphology. Cognition, 28(3), 297-332. doi: 10.1016/0010-0277(88)90017-0
Caramazza, A., & Miozzo, M. (1997). The relation between syntactic and phonological knowledge in lexical access: evidence from the 'tip-of-the-tongue' phenomenon. Cognition, 64(3), 309-343. doi: 10.1016/80010-0277(97)00031-0
Carello, C., Lukatela, G., & Turvey, M. (1988). Rapid naming is affected by association but not by syntax. Memory & Cognition, 16(3), 187-195. doi: 10.3758/BF03197751
Chernigovskaya, T, Gor, K., Svistunova, T, Petrova, T, & Khrakovs- kaya, M. (2009). [Mental lexicon in decay of the language system in patients with aphasia: Experimental study of the verb morphology], Voprosy Yazykoznaniya, (5), 3-17. (Russian).
Christianson, K., Johnson, R. L., & Rayner, K. (2005). Letter transpositions within and across morphemes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(6), 1327-1339. doi: 10.1037/0278-7393.31.6.1327
Cole, P., Beauvillain, C., Pavard, B., & Segui, J. (1986). Organisation morphologique et acces au lexique. L'annee psy- chologique, 86(3), 349-365. doi: 10.3406/psy.l986.29154
Cole, P., Beauvillain, C., & Segui, J. (1989). On the representation and processing of prefixed and suffixed derived words: A differential frequency effect. Journal of Memory and Language, 28(1), 1-13. doi: 10.1016/0749-596X(89)90025-9
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). ORC: a dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204-256. doi: 10.1037/0033-295X.108.1.204
Crepaldi, D., Rastle, K., & Davis, C. J. (2010). Morphemes in their place: Evidence for position-specific identification of suffixes. Memory & Cognition, 38(3), 312-321. doi: 10.3758/ MC.38.3.312
Crepaldi, D., Rastle, K., Davis, C. J., & Lupker, S.J. (2013). Seeing stems everywhere: Position-independent identification of stem morphemes. Journal of Experimental Psychology: Human Perception and Performance, 39(2), 510-525. doi: 10.1037/a0029713
Deutsch, A., Frost, R., Pelleg, S., Pollatsek, A., & Rayner, K. (2003). Early morphological effects in reading: Evidence from parafoveal preview benefit in Hebrew. Psychonomic Bulletin & Review, 10(2), 415-422. doi: 10.3758/BF03196500
Deutsch, A., & Meir, A. (2011). The role of the root morpheme in mediating word production in Hebrew. Language and Cognitive Processes, 26(4-6), 716-744. doi: 10.1080/0169096-5.2010.496238
Diependaele, K., Brysbaert, M., & Neri, P. (2012). How noisy is lexical decision? Frontiers in Psychology, 3, 348. doi: 10.3389/ipsyg.2012.00348
Diependaele, K., Morris, J., Serota, R.M., Bertrand, D., & Grainger, J. (2013). Breaking boundaries: Letter transpositions and morphological processing. Language and Cognitive Processes, 28(7), 988-1003. doi: 10.1080/01690965.2012.719082
Diependaele, K., Sandra, D., & Grainger, J. (2005). Masked cross- modal morphological priming: Unravelling morpho-ortho- graphic and morpho-semantic influences in early word recognition. Language and Cognitive Processes, 20(1-2), 75-114. doi: 10.1080/01690960444000197
Diependaele, K., Sandra, D., & Grainger, J. (2009). Semantic transparency and masked morphological priming: The case of prefixed words. Memory & Cognition, 37(6), 895-908. doi: 10.3758/MC.37.6.895
Dohmes, P., Zwitserlood, P., & Bölte, J. (2004). The impact of semantic transparency of morphologically complex words on picture naming. Brain and Language, 90(1), 203-212. doi: 10.1016/S0093-934X(03)00433-4
Downing, P. (1977). On the creation and use of English compound nouns. Language, 53(4), 810-842. doi: 10.2307/412913
Dunabeitia, J. A., Kinoshita, S., Carreiras, M., 8r Norris, D. (2011). Is morpho-orthographic decomposition purely orthographic? Evidence from masked priming in the same-different task. Language and Cognitive Processes, 26(4-6), 509-529. doi: 10.1080/01690965.2010.499215
Dunabeitia, J. A., Perea, M., & Carreiras, M. (2007). Do trans- posed-letter similarity effects occur at a morpheme level? Evidence for morpho-orthographic decomposition. Cognition, 105(3), 691-703. doi: 10.3758/sl3423-014-0609-2
Dunabeitia, J. A., Perea, M., 8r Carreiras, M. (2014). Revisiting letter transpositions within and across morphemic boundaries. Psychonomic Bulletin & Review, 21(6), 1557-1575.
Feldman, L. B. (1990). Morphological relationships revealed through the repetition priming task. In Haskins Laboratories Status Report on Speech Research (pp. 101-109). Retrieved from http://www.haskins.yale.edu/sr/SR101/SR101 07.pdf.
Feldman, L. B., & Bentin, S. (1994). Morphological analysis of disrupted morphemes: Evidence from Hebrew. The Quarterly Journal of Experimental Psychology, 47A(2), 407-435.
Feldman, L.B., & Fowler, C. A. (1987). The inflected noun system in Serbo-Croatian: Lexical representation of morphological structure. Memory & Cognition, 15(1), 1-12. doi: 10.3758/ BF03197707
Feldman, L. B., & Moskovljevic, J. (1987). Repetition priming is not purely episodic in origin. Journal of Experimental Psychology: Learning Memory, and Cognition, 13(4), 573-581. doi: 10.1037/0278-7393.13.4,573
Feldman, L.B., O’Connor, P.A., & Moscoso del Prado Martin, F. (2009). Early morphological processing is morphose- mantic and not simply morpho-orthographic: A violation of form-then-meaning accounts of word recognition. Psychonomic Bulletin & Review, 16(4), 684-691. doi: 10.3758/ PBR. 16.4.684
Feldman, L.B., & Prostko, B. (2002). Graded aspects of morphological processing: Task and processing time. Brain and Language, 81(1), 12-27. doi: 10.1006/brln.2001.2503
Feldman, L. B., Soltano, E. G., Pastizzo, M. J., & Francis, S. E. (2004). What do graded effects of semantic transparency reveal about morphological processing? Brain and Language, 90(1), 17-30. doi: 10.1016/80093-934X103100416-4
Ferrari, E, & Kacinik, N. (2014). Linearity and word internal structure in the visual processing of Italian complex words. University of Pennsylvania Working Papers in Linguistics, 20(1), 11. Retrieved from http://repository.upenn.edu/pwpl/vol20/issl/ll.
Forster, K.I. (1976). Accessing the mental lexicon. In R. Wales, & E. Walker (Eds.), New approaches to language mechanisms (pp. 257-287). Amsterdam: North-Holland Publ.
Forster, K.I., & Azuma, T. (2000). Masked priming for prefixed words with bound stems: Does submit prime permit? Language and Cognitive Processes, 15(4-5), 539-561. doi:10.1080/01690960050119698
Fowler, C. A., Napps, S.E., & Feldman, L. (1985). Relations among regular and irregular morphologically related words in the lexicon as revealed by repetition priming. Memory & Cognition, 13(3), 241-255. doi: 10.3758/BF03197687
Frauenfelder, U.H., & Schreuder, R. (1992). Constraining psycholinguistic models of morphological processing and representation: The role ofproductivity. In G. Booij, & J. van Marie (Eds.), Yearbook of morphology (pp. 165-183). Netherlands: Kluwer Academic Publishers, doi: 10.1007/978-94-011-2516-1 10
Giraudo, H. (2005). Un modele supralexical de representation de la morphologic derivationnelle en fran^ais. L'annee psy- chologique, 105(1), 171-195. doi: 10.3406/psy.2005.3825
Giraudo, H., & Grainger, J. (2000). Effects of prime word frequency and cumulative root frequency in masked morphological priming. Language and Cognitive Processes, 15(4-5), 421-444. doi: 10.1080/01690960050119652
Giraudo, H., & Voga, M. (2013). Prefix units within the mental lexicon. In N. Hathout, F. Montermini, & J. Tseng (Eds.), LINCOM Studies in Theoretical Linguistics 51 (LSTL 51). Morphology in Toulouse. Selected Proceedings of Decem- brettes 7 (pp. 61-78).
Giraudo, H., & Voga, M. (2014). Measuring morphology: the tip of the iceberg? A retrospective on 10 years of morphological processing. Cahiers de Grammaire, Equipe de Recherche en Syntaxe et Semantique (ERSS).
Grainger, J., & Segui, J. (1990). Neighborhood frequency effects in visual word recognition: A comparison of lexical decision and masked identification latencies. Perception & Psychophysics, 47(2), 191-198. doi: 10.3758/BF03205983
Heide, J. (2010). Warum vertragen anders ist als vergiften und vergessen Ein Einblick in unser mentales Lexikon. In M. Wahl, C. Stahn, S. Hanne, & T. Fritzsche (Eds.), Spektrum Patholin- guistik 3 (pp. 71-88). Universitätsverlag Potsdam. (German).
Huang, Y.T., & Pinker, S. (2010). Lexical semantics and irregular inflection. Language and Cognitive Processes, 25(10), 1411-1461. doi: 10.1080/016909610035894-76
Hyönä, J., Laine, M., & Niemi, J. (1995). Effects of a word's morphological complexity on readers' eye fixation patterns. In J. Findlay, R. Walker, & R. Kentridge (Eds.), Eye movement research: Mechanisms, processes and applications. Visual information processing Vol. 6 (pp. 445-452). Amsterdam: North-Holland.
Janssen, D. P., Bordag, D., & Pechmann, T. (2004). Morphological encoding and morphological structures in German. In T. Pechmann, & C. Habel (Eds.), Multidisciplinary Approaches to Language Production (pp. 473-528). Berlin: Mouton de Gruyter.
Järvikivi, J., & Niemi, J. (2002). Form-based representation in the mental lexicon: Priming (with) bound stem allomorphs in Finnish. Brain and Language, 81(1), 412-423. doi: 10.1006/brln.2001.2534
Juhasz, B.J., & Berkowitz, R.N. (2011). Effects of morphological families on English compound word recognition: A multitask investigation. Language and Cognitive Processes, 26(4-6), 653-682. doi: 10.1080/01690965.2010.498668
Juhasz, B. J., Pollatsek, A., Hyönä, J., Drieghe, D., & Rayner, K. (2009). Parafoveal processing within and between words. The Quarterly Journal of Experimental Psychology, 62(7), 1356-1376. doi: 10.1080/17470210802400010
Kambe, G. (2004). Parafoveal processing of prefixed words during eye fixations in reading: Evidence against morphological influences on parafoveal preprocessing. Perception & Psychophysics, 66(2), 279-292. doi: 10.3758/BF03194879
Kazanina, N., Dukova-Zheleva, G., Geber, D., Kharlamov, V, & Tonciulescu, K. (2008). Decomposition into multiple morphemes during lexical access: A masked priming study of Russian nouns. Language and Cognitive Processes, 23(6), 800-823. doi: 10.1080/01690960701799635
Kehayia, E., & Jarema, G. (1994). Morphological priming (or prim\# ing?) of inflected verb forms: A comparative study. Journal of Neurolinguistics, 8(2), 83-94. doi: 10.1016/0911-6044(94)90018-3
Keuleers, E., & Brysbaert, M. (2010). Wuggy: A multilingual pseudoword generator. Behavior Research Methods, 42(3), 627-633. doi: 10.3758/BRM.42.3.627
Kostic, A., & Havelka, J. (2002). Processing of verb tense. Psi- hologija, 35(3-4), 299-316. doi: 10.2298/PSI0203299K
Kostic, A., & Mirkovic, J. (2002). Processing of inflected nouns and levels of cognitive sensitivity. Psihologija, 35(3-4), 287-297. doi: 10.2298/PSI0203287K
Kuperman, V, Bertram, R., & Baayen, R.H. (2008). Morphological dynamics in compound processing. Language and Cognitive Processes, 23(7-8), 1089-1132. doi: 10.1080/01690960802193688
Kuperman, V, Bertram, R., & Baayen, R.H. (2010). Processing trade-offs in the reading of Dutch derived words. Journal of Memory and Language, 62(2), 83-97. doi: 10.1016/i. jml.2009.10.001
Kuperman, V, Drieghe, D., Keuleers, E., & Brysbaert, M. (2013). How strongly do word reading times and lexical decision times correlate? Combining data from eye movement corpora and megastudies. The Quarterly Journal of Experimental Psychology, 66(3), 563-580. doi: 10.1080/17470218.2012.658820 Kuperman, V, Schreuder, R., Bertram, R., &Baayen, R.H. (2009).
Reading polymorphemic Dutch compounds: toward a multiple route model of lexical processing. Journal of Experimental Psychology: Human Perception and Performance, 35(3), 876-895. doi: 10.1037/a0013484
Laudanna, A., Burani, C., & Cermele, A. (1994). Prefixes as processing units. Language and Cognitive Processes, 9(3), 295-316. doi: 10.1080/01690969408402121
Levelt, W.J., Roelofs, A., 8r Meyer, A.S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences, 22(01), 1-38. doi: 10.1017/80140525X99001776
Libben, G. (2003). Morphological parsing and morphological structure. In A. Egbert, & D. Sandra (Eds.), Reading complex words (pp. 221-239). Amsterdam: Kluwer, doi: 10.1007/978-1-4757-3720-2 10
Libben, G., & Weber, S. (2012). Semantic transparency, compounding, and the nature of independent variables. In F. Rainer, F. Gardani, H. C. Luschützky, & W. U. Dressier (Eds.), Morphology and Meaning: Selected papers from the 15th International Morphology Meeting Vienna, February 2012 (pp. 205-221). Amsterdam: John Benjamins Publishing Company.
Lima, S. D. (1987). Morphological analysis in sentence reading. Journal of Memory and Language, 26(1), 84-99. doi: 10.1016/0749-596X187)90064-7
Lima, S.D., & Pollatsek, A. (1983). Lexical access via an orthographic code? The basic orthographic syllabic structure (BOSS) reconsidered. Journal of Verbal Learning and Verbal Behavior, 22(3), 310-332. doi: 10.1016/ 80022-5371183)90215-3
Longtin, С.-M., & Meunier, F. (2005). Morphological decomposition in early visual word processing. Journal of Memory and Language, 53(1), 26-41. doi: 10.1016/j.jml.2005.0-2.008
Longtin, С.-M., Segui, J., & Halle, P.A. (2003). Morphological priming without morphological relationship. Language and Cognitive Processes, 18(3), 313-334. doi: 10.1080/01690960244000036
Lukatela, G., Gligorijevic, B., Kostic, A., & Turvey, M.T. (1980). Representation of inflected nouns in the internal lexicon. Memory & Cognition, 8(5), 415-423. doi: 10.3758/ BF03211138
Lukatela, G., Kostic, A., Feldman, L.B., & Turvey, M.T. (1983). Grammatical priming of inflected nouns. Memory & Cognition, 11(1), 59-63. doi: 10.3758/BF03197662
MacKay, D. G. (1978). Derivational rules and the internal lexicon. Journal of Verbal Learning and Verbal Behavior, 17(1), 61-71. doi: 10.1016/80022-5371178)90529-7
Manelis, L., & Tharp, D.A. (1977). The processing of affixed words. Memory & Cognition, 5(6), 690-695. doi: 10.3758/ BF03197417
Manouilidou, C. (2007). Thematic constraints in deverbal word formation: psycholinguistic evidence from pseudo-words. In Proceedings of the 7th International Conference on Greek Linguistics. UK: University of York.
Marjanovic, K., Manouilidou, C., & Marvin, T. (2013). Word-formation rules in Slovenian agentive deverbal nominalization: A psycholinguistic study based on pseudo-words. Slovene Linguistic Studies, 9, 93-109.
Marslen-Wilson, WD. (1989). Access and integration: Projecting sound onto meaning. In WD. Marslen-Wilson (Ed.), Lexical representation and process (pp. 3-24). Cambridge, MA: The MIT Press.
Marslen-Wilson, W. D., Bozic, M., & Randall, B. (2008). Early decomposition in visual word recognition: Dissociating morphology, form, and meaning. Language and Cognitive Processes, 23(3), 394-421. doi: 10.1080/01690960701588004
Marslen-Wilson, W.D., Ford,M., Older, L., & Xiaolin, Z. (1996). The combinatorial lexicon: Priming derivational affixes. In G.W. Cottrell (Ed.), Proceedings of the Eighteenth Annual Conference of the Cognitive Science Society: July 12-15, 1996, University of California, San Diego (pp. 223-227). NJ: Elrlbaum.
Marslen-Wilson, W. D., Tyler, L. K., Waksler, R., & Older, L. (1994). Morphology and meaning in the English mental lexicon. Psychological Review, 101(1), 3-33. doi: 10.1037/0033-295X. 101.1.3
McClelland, J. L., & Patterson, K. (2002). Rules or connections in past-tense inflections: What does the evidence rule out? Trends in Cognitive Sciences, 6(11), 465-472. doi: 10.1016/ SI364-6613(02101993-9
McClelland, J. L., & Rumeihart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88(5), 375-407. doi: 10.1037/0033-295X.88.5.375
McCormick, S. E, Rastle, K., & Davis, M. H. (2008). Is there a ‘fete’ in ‘fetish’? Effects of orthographic opacity on morpho- orthographic segmentation in visual word recognition. Journal of Memory and Language, 58(2), 307-326. doi: 10.1016/i. jml.2007.05.006
Meunier, E, & Longtin, C.-M. (2007). Morphological decomposition and semantic integration in word processing. Journal of Memory and Language, 56(4), 457-471. doi: 10.1016/i. iml.2006.11.005
Meunier, E, & Segui, J. (1999). Morphological priming effect: The role of surface frequency. Brain and Language, 68(1), 54-60. doi: 10.1006/brln.l999.2098
Meyer, A. S. (1990). The time course of phonological encoding in language production: The encoding of successive syllables of a word. Journal of Memory and Language, 29(5), 524-545. doi: 10.1016/0749-596X(90)90050-A
Meyer, A. S. (1991). The time course of phonological encoding in language production: Phonological encoding inside a syllable. Journal of Memory and Language, 30(1), 69-89. doi: 10.1016/0749-596X(91)90011-8
Milin, P., Durdevic, D. E, & Moscoso del Prado Martin, E (2009). The simultaneous effects of inflectional paradigms and classes on lexical recognition: Evidence from Serbian. Journal of Memory and Language, 60(1), 50-64. doi: 10.1016/j.jml.2008.08.007
Morton, J. (1969). Interaction of information in word recognition. Psychological Review, 76(2), 165-178. doi: 10.1037/h0027366
Morton, J. (1970). A functional model for memory. In D. Norman (Ed.), Models of human memory (pp. 203-254). New York: Academic Press.
Moscoso del Prado Martin, E, Kostic, A., & Baayen, R.H. (2004). Putting the bits together: An information theoretical perspective on morphological processing. Cognition, 94(1), 1-18. doi: 10.1016/i.coenition.2003.10.015
New, B., Pallier, C., Ferrand, L., & Matos, R. (2001). Une base de donne 'es lexicales du fran^ais contemporain sur internet: LEXIQUE [A lexical database on the internet for contemporary French: LEXIQUE], ІАппее Psychologique, 101(3), 447-462.
Pastizzo, M. J., & Feldman, L. B. (2004). Morphological processing: A comparison between free and bound stem facilitation. Brain and Language, 90(1), 31-39. doi: 10.1016/ 80093-934X103100417-6
Paterson, K.B., Alcock, A., & Liversedge, S.P. (2011). Morphological priming during reading: Evidence from eye movements. Language and Cognitive Processes, 26(4-6), 600-623. doi: 10.1080/01690965.2010.485392
Pinker, S. (1999). Words and rules: The ingredients of language. New York: HarperCollins Publishers.
Plaut, D. C., 8r Gonnerman, L.M. (2000). Are non-seman- tic morphological effects incompatible with a distributed connectionist approach to lexical processing? Language and Cognitive Processes, 15(4-5), 445-485. doi: 10.1080/01690960050119661
Pollatsek, A., Drieghe, D., Stockall, L., & de Almeida, R. G. (2010). The interpretation of ambiguous trimorphemic words in sentence context. Psychonomic Bulletin & Review, 17(1), 88-94. doi: 10.3758/PBR.17.1.88
Pollatsek, A., & Hyönä, J. (2005). The role of semantic transparency in the processing of Finnish compound words. Language and Cognitive Processes, 20(1-2), 261-290. doi: 10.1080/01690960444000098
Rapp, B. G. (1992). The nature of sublexical orthographic organization: The bigram trough hypothesis examined. Journal of Memory and Language, 31(1), 33-53. doi: 10.1016/0749-596X(92)90004-H
Rastle, K., Davis, M. H., Marslen-Wilson, W. D., & Tyler, L. K. (2000). Morphological and semantic effects in visual word recognition: A time-course study. Language and Cognitive Processes, 15(4-5), 507-537. doi: 10.1080/01690960050119689
Raveh, M. (2002). The contribution of frequency and semantic similarity to morphological processing. Brain and Language, 81(1). 312-325. doi: 10.1006/brln.2001.2527
Raveh, M., & Rueckl, J.G. (2000). Equivalent effects of inflected and derived primes: Long-term morphological priming in fragment completion and lexical decision. Journal of Memory and Language, 42(1), 103-119. doi: 10.1006/ jmla.1999.2673
Rayner, K., White, S. J., Johnson, R. L., & Liversedge, S. P. (2006). Rae ding wrods with jubmled lettres. There is a cost. Psychological Science, 17(3), 192-193. doi: 10.1111/i. 1467-9280.2006.01684.X
Reid, A. A., & Marslen-Wilson, W. D. (2000). Complexity and alternation in the Polish mental lexicon. In ISCA Tutorial and Research Workshop (ITRW) on Spoken Word Access Processes. Nijmegen, The Netherlands.
Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42(1), 107-142. doi: 10.1016/0010-0277(92)90041-F
Roelofs, A. (1996). Serial order in planning the production of successive morphemes of a word. Journal of Memory and Language, 35(6), 854-876. doi: 10.1006/jmla.l996.0044
Roelofs, A., & Baayen, H. (2002). Morphology by itself in planning the production of spoken words. Psychonomic Bulletin & Review, 9(1), 132-138. doi: 10.3758/BF031962-69
Roelofs, A., Meyer, A. S., & Levelt, W. J. (1998). A case for the lemma/lexeme distinction in models of speaking: Comment on Caramazza and Miozzo (1997). Cognition, 69(2), 219-230.
Rouibah, A., & Taft, M. (2001). The role of syllabic structure in French visual word recognition. Memory & Cognition, 29(2), 373-381. doi: 10.3758/BF03194932
Rueckl, J. G., & Rimzhim, A. (2011). On the interaction of letter transpositions and morphemic boundaries. Language and cognitive processes, 26(4-6), 482-508. doi: 10.1080/0169-0965.2010.500020
Sahel, S., Nottbusch, G., Grimm, A., & Weingarten, R. (2008). Written production of German compounds: Effects of lexical frequency and semantic transparency. Written Language & Literacy, 11(2), 211-227. doi: 10.1075/wll.ll.2.06sah
Sänchez-Casas, R., Igoa, J.M., & Garcia-Albea, J.E. (2003). On the representation of inflections and derivations: Data from Spanish. Journal of Psycholinguistic Research, 32(6), 621-668. doi: 10.1023/A:1026123315293
Sandra, D. (1994). Morphology in the reader's mental lexicon. Duisburg Papers on Research in Language and Culture. Vol. 21. Frankfurt: P. Lang.
Schreuder, R. (1990). Lexical processing of verbs with separable particles. In G. Booiji, & J. van Marie (Eds.), Yearbook of Morphology, 3 (pp. 65-79). Dordrecht, Netherlands: Foris Publications.
Schreuder, R., & Baayen, R.H. (1995). Modelling morphological processing. In L.B. Feldman (Ed.), Morphological aspects of language processing (pp. 131-156). Hillsdale, NJ: Erlbaum.
Schreuder, R., & Baayen, R.H. (1997). How complex simplex words can be. Journal of Memory and Language, 37(1), 118-139. doi: 10.1006/jmla.l997.2510
Schreuder, R., Grendel, M., Poulisse, N., Roelofs, A., & van de Voort, M. (1990). Lexical processing, morphological complexity and reading. In D. Balota, G. B. Flores d'Arcais null, & K. Rayner (Eds.), Comprehension processes in reading (pp. 125-141). New York Routledge.
Schriefers, H., Friederici, A., & Graetz, P. (1992). Inflectional and derivational morphology in the mental lexicon: Symmetries and asymmetries in repetition priming. The Quarterly Journal of Experimental Psychology. Section A: Human Experimental Psychology, 44(2), 373-390.
Seidenberg, M. S. (1987). Sublexical structures in visual word recognition: Access units or orthographic redundancy? In M. Coltheart (Ed.), Attention and performance XII: The psychology of reading (pp. 245-263). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Sekerina, I. (1997). [Psycholinguistics], In A. Kibrik, I. Kobozeva, & I. Sekerina (Eds.), [Basic trends in contemporary American linguistics: A collection of essays] (pp. 231-260). Moscow: Izdatel’stvo Moskovskogo universiteta. (Russian).
Seva, N., & Kostic, A. (2003). Annotated corpus and the empirical evaluation of probability estimates of grammatical forms. Psihologija, 36(3), 255-270. doi: 10.2298/PSI0303255S
Smolik F. (2010). Inflectional suffix priming in Czech verbs and nouns. In S. Ohlsson, & R. Catrambone (Eds.), Proceedings of the 32nd annual conference of the Cognitive Science Society (pp. 1667-1672). Austin, TX: Cognitive Science Society.
Smolka, E., Preller, K.H., & Eulitz, С. (2014). ‘Verstehen (‘understand’) primes ‘stehen (‘stand’): Morphological structure overrides semantic compositionality in the lexical representation of German complex verbs. Journal of Memory and Language, 72, 16-36. doi: 10.1016/j.jml.2013.12.002
Smolka, E., Zwitserlood, P., & Rösler, F. (2007). Stem access in regular and irregular inflection: Evidence from German participles. Journal of Memory and Language, 57(3), 325-347. doi: 10.1016/j.jml.2007.04.005
Stanners, R. E, Neiser, J.J., & Painton, S. (1979). Memory representation for prefixed words. Journal of Verbal Learning and Verbal Behavior, 18(6), 733-743. doi: 10.1016/ 50022-5371(79)90439-0
Steinberg, D. D. (1973). Phonology, reading, and Chomsky and Halle's optimal orthography. Journal of Psycholinguistic Research, 2(3), 239-258. doi: 10.1007/BF01067104
Svistunova, T. I. (2008). Organizatsiya mentalnogo leksikona: formirovanie v ontogeneze i raspad pri narusheniyakh yazykovoy sistemy glagolnoy slovoizmenitelnoy morpholo- gii. [Structure of the mental lexicon: ontogenetic formation of the verb inflectional morphology and its decay in deterioration of the language system (an experimental study)]. Unpublished doctoral dissertation, Saint-Petersburg State University. (Russian).
Taft, M. (1979a). Lexical access via an orthographic code: The basic orthographic syllabic structure (BOSS). Journal of Verbal Learning and Verbal Behavior, 18(1), 21-39. doi: 10.1016/80022-5371(79)90544-9
Taft, M. (1979b). Recognition of affixed words and the word frequency effect. Memory & Cognition, 7(4), 263-272. Retrieved from http://www2.psy.unsw.edu.au/Users/mtaft/MandC1979.PDF. doi: 10.3758/BF03197599
Taft, M. (1981). Prefix stripping revisited. Journal of Verbal Learning and Verbal Behavior, 20(3), 289-297. Retrieved from http://www2.psy.unsw.edu.au/Users/mtaft/TVLVB1981.PDF, doi: 10.1016/80022-5371(81)90439-4
Taft, M. (1987). Morphographic processing: The BOSS re- emerges. In M. Coltheart (Ed.), Attention and performance XII: The psychology of reading (pp. 265-279). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc. Retrieved from http://www2.psy.unsw.edu.au/Users/mtaft/Taftl987.PDF.
Taft, M. (1994). Interactive-activation as a framework for understanding morphological processing. Language and cognitive processes, 9(3), 271-294. doi: 10.1080/0169096940-8402120
Taft, M., & Forster, К. I. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14(6), 638-647. Retrieved from http://www2.psy.unsw.edu.au/Users/mtaft/IVLVB-1975.PDF. doi: 10.1016/ S0022-5371(75)80051-X
Taft, M., & Forster, К. I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. Journal of Verbal Learning and Verbal Behavior, 15(6), 607-620. Retrieved from http://www2.psy.unsw.edu.au/Users/mtaft/TVLVB1976.PDF. doi: 10.1016/0022-5371(76)90054-2
Taft, M., & Nguyen-Hoan, M. (2010). A sticky stick? The locus of morphological representation in the lexicon. Language and Cognitive Processes, 25(2), 277-296. doi: 10.1080/01690960903043261
Taft, M., & Nillsen, C. (2012). Morphological decomposition and the transposed-letter (TL) position effect. Language and Cognitive Processes, iFirst, 1-22. doi: 10.1080/01690965.2012.679662
Treisman, A.M. (1961). Attention and speech. Unpublished doctoral dissertation, University of Oxford.
Treisman, A.M. (1986). Features and objects in visual processing. Scientific American, 255(5), 114-125.
VanWagenen, S., & Pertsova, K. (2014). Asymmetries in priming of verbal and nominal inflectional affixes in Russian. UCLA Working Papers in Linguistics, 18, 49-59. Retrieved from http://www.linguistics.uda.edu/faciliti/wpl/issues/wpll8/papers/svwpertsova.pdf.
Voga, M., & Giraudo, H. (2009). Pseudo-family size influences the processing of French inflections: evidence in favor of a supralexical account. In F. Montermini, G. Boye, & J. Tseng (Eds.), Selected Proceedings of the 6th Decembrettes: Morphology in Bordeaux (pp. 148-155). Somerville, MA: Cascadilla Proceedings Project.
White, S.J., Johnson, R.L., Liversedge, S.P., & Rayner, K. (2008). Eye movements when reading transposed text: the importance of word-beginning letters. Journal of Experimental Psychology: Human Perception and Performance, 34(5), 1261-1276. doi: 10.1037/0096-1523.34.5.1261
Will, U, Nottbusch, G., & Weingarten, R. (2006). Linguistic units in word typing: Effects of word presentation modes and typing delay. Written Language & Literacy, 9(1), 153-176. doi: 10.1075/wll.9.1.10wil
Yang, C. (2002). Knowledge and learning in natural language. Oxford: Oxford University Press.
Zwitserlood, P., Bölte, J., & Dohmes, P. (2000). Morphological effects on speech production: Evidence from picture naming. Language and Cognitive Processes, 15(4-5), 563-591. doi: 10.1080/01690960050119706