This article is published under a Creative Commons license and not by the author of the article. So if you find any inaccuracies, you can correct them by updating the article.

«Нисходящее» и «восходящее» совместное внимание в невербальной коммуникации



Михаил В. Зотов
Наталия Е. Андрианова
Алексей П. Войт
Published: March 24, 2015
Latest article update: Sept. 14, 2022
This article is published under the license




Abstract
Многие теории совместного внимания рассматривают его как низкоуровневый автоматизированный процесс прослеживания направления взгляда человека по ориентации его головы и глаз. Между тем ориентация головы и глаз человека является недостаточным источником информации об объекте его внимания. Проведен эксперимент, в ходе которого взрослые испытуемые выполняли задачу саккадической детекции объектов внимания участников невербальных коммуникативных сцен в двух условиях: (1) после просмотра видеофрагмента, позволяющего сформировать представление о контексте коммуникативной ситуации; (2) при отсутствии информации о коммуникативном контексте. Наряду с этим, варьировалось время экспозиции визуальной информации, необходимой для оценки направления взгляда персонажей. Испытуемые, обладавшие информацией о коммуникативном контексте, в отличие от лиц, не обладавших такой информацией, демонстрировали высокую эффективность идентификации и саккадической детекции «малозаметных» объектов внимания персонажей, независимо от степени доступности информации о направлении их взгляда. Результаты второго эксперимента показали, что при восприятии невербальных коммуникативных сцен испытуемые избирательно запоминают и поддерживают в памяти информацию о визуально-пространственных признаках стимулов, рассматриваемых в качестве потенциальных объектов внимания персонажей. В целом работа показала, что в невербальных коммуникативных ситуациях идентификация объектов внимания другого человека обеспечивается сложными высокоуровневыми процессами, сходными с процессами идентификации референтов речевых высказываний и указательных жестов.
Keywords
Зрительный поиск, коммуникативный контекст, социальная перцепция, невербальная коммуникация, движения глаз, направление взгляда, совместное внимание, «модель психического»
Введение
Совместное внимание (joint attention), понимаемое как способность человека обращать внимание на те же объект или событие, на которые обращает внимание другой человек, имеет важнейшее значение для процессов коммуникации (Фаликман, 2006; Ахутина и др., 2013). Так, при построении высказывания говорящий обычно учитывает, какой объект (событие) или какие аспекты этого объекта (события) находятся в фокусе внимания собеседника (Ирисханова, 2014).
В современных исследованиях доминирует взгляд на совместное внимание как на относительно элементарный процесс прослеживания взором направления взора собеседника (gaze following) (Emery, 2000; Langton et al., 2000; Frischen et al., 2007). Многие работы опираются на концепцию Дж. Баттеруорта, постулирующую три утверждения: (1) совместное внимание является «одним из наиболее элементарных когнитивных процессов» (Butterworth, Jarrett, 1991, р. 71); (2) совместное внимание основывается на механизме экстраполяции линии взгляда, предполагающем, что идентификация объекта взгляда другого человека осуществляется на основе построения воображаемой линии в пространстве в соответствии с ориентацией его головы и глаз (там же); (3) реализация совместного внимания не требует выдвижения предположений о намерениях другого человека (там же).
Развивая эти утверждения, некоторые авторы сосредоточились на изучении таких вопросов, как степень точности, с которой люди способны оценивать угол направления взгляда другого человека (Bock et al., 2008), анализ вклада положения тела, поворота головы и ориентации глаз в определение линии взгляда (Todorovic, 2006; Langton et al., 2000) и т.п.
Во многих работах использовалась процедура «подсказки взглядом» (gaze-cueing paradigm), представляющая собой модификацию методики подсказки М. Познера. Данная процедура состоит в том, что сначала в центре экрана испытуемый видит реалистичное или схематичное изображение глаз или лица человека, смотрящего в правую или левую сторону. Затем в правой или левой части экрана появляется целевой стимул, на который испытуемый должен прореагировать. Установлено, что, даже зная о неинформативности лица как подсказки, люди непроизвольно ориентируют внимание на ту область экрана, на которую обращен взгляд изображенного человека (Friesen, Kingstone, 1998). На основе этих данных делается вывод о том, что совместное внимание обеспечивается автоматизированными процессами отслеживания направления взгляда (Friesen, Kingstone, 1998; Friesen et al., 2005; Frischen et al., 2007), являющимися «частью примитивного ориентировочного рефлекса» (Emery, 2000; Shepherd, 2010).
В то же время ориентация головы и глаз другого индивида является недостаточным источником информации об объекте его внимания. Немного изменим пример М. Томаселло (2011) и представим человека, взглянувшего на пробегающего мимо кролика. Как мы определим, что именно является объектом его внимания — сам кролик, его лапы, уши, бег и т. д.? Как мы определим, что объектом внимания человека является именно кролик, а не любой другой объект (например, куст), находящийся на линии его взгляда? Между тем при повседневном общении мы легко идентифицируем объект внимания собеседника в условиях, когда его взгляд направлен на множество предметов. На чем может основываться такая идентификация?
Отвечая на этот вопрос, М. Томаселло и его сотрудники предлагают различать совместное внимание, ведомое «восходящими» (bottom-up) процессами, и совместное внимание, ведомое «нисходящими» (top-down) процессами (Томаселло, 2011; Carpenter, Liebal, 2011).
«Восходящее» совместное внимание (bottom-up joint attention) основывается на информации о перцептивных характеристиках стимулов. Если какой-либо стимул или событие, вследствие своей «заметности» (saliency), необычности и т. д., привлекает наше непроизвольное внимание, мы можем сделать вывод о том, что этот стимул или это событие также привлекает внимание нашего собеседника. Например, когда справа мы слышим звук разбивающейся чашки и видим, как собеседник поворачивает голову в этом направлении, мы делаем вывод о том, что его внимание, так же как и наше, привлечено этим событием. Если собеседник поворачивает голову вправо, и в зоне его взгляда наше внимание привлекает какой-то яркий или необычный предмет, мы можем сделать вывод, что именно на данный предмет обращено внимание собеседника. В эксперименте А. Боржи с соавторами (Borji et al., 2014; эксперимент 2) исследовалось распределение фиксаций взгляда испытуемых в процессе свободного рассматривания фотографических изображений людей, смотрящих на какие-либо предметы в своем окружении. Установлено, что испытуемые преимущественно фиксировали взгляд на «визуально ярких» (salient) объектах, расположенных в зоне взгляда наблюдаемых людей. Эту зону взгляда («gaze тар») авторы предлагают рассматривать как конус в направлении взгляда наблюдаемого человека, вершина которого приходится на область его глаз. В свете обсуждаемой темы результаты эксперимента А. Боржи и соавт. можно интерпретировать следующим образом. Испытуемые не осуществляют тонкой дифференцированной оценки ориентации позы, головы и глаз наблюдаемого человека, позволяющей с точностью до нескольких градусов рассчитать линию его взгляда и идентифицировать расположенные на данной линии объекты. Вместо этого они проводят грубую, приблизительную оценку ориентации позы, головы и глаз наблюдаемого человека для выделения зоны его взгляда. Затем они идентифицируют попадающие в эту зону «заметные» объекты, к которым можно отнести предметы с высоким уровнем «визуальной яркости» (visual saliency) и биологически значимые объекты, например, лица людей.
«Нисходящее» совместное внимание (top-down joint attention) основывается на информации о смысловом контексте коммуникации, например, знании о том, что какой-либо предмет является новым или значимым для собеседника (но не для нас). В эксперименте Н. Ах- тар, М. Карпентер и М. Томаселло (Akhtar et al., 1996) ребенок, его мама и экспериментатор играли с тремя новыми предметами. Потом мама выходила из комнаты. Экспериментатор извлекал четвертый новый пред
мет и играл в него с ребенком до тех пор, пока этот предмет не терял для ребенка новизну. Когда мама возвращалась в комнату, она смотрела на все четыре предмета (расположенные рядом) и восклицала, обращаясь к ребенку: «Ух ты! Это же газзер! Газзер!», затем просила дать ей «газзер». Дети в возрасте 24 месяцев идентифицировали новый для мамы четвертый предмет как объект ее внимания и относили слово «газзер» именно к нему (несмотря на то, что для них самих все четыре предмета были в равной степени знакомы). В дальнейшем были реализованы различные модификации этого эксперимента (Tomasello, Haberl, 2003; Moll et al., 2006).
Замечательный эксперимент H. Ахтар и соавторов позволяет сделать два вывода. Во-первых, идентификация объектов внимания другого человека тесно связана с определением референтов1 (Под термином «референт» понимается объект внеязыковой действительности, являющийся предметом обсуждения и/или взаимодействия участников коммуникативной ситуации.) его речевых выражений (в данном случае слова «газзер») и указательных жестов (в сходном эксперименте М. Томаселло и К. Ха- берль (Tomasello, Haberl, 2003) мама указывала рукой на предметы). Во-вторых, такая идентификация предполагает способность к рассмотрению ситуации одновременно с нескольких точек зрения или перспектив. Действительно, чтобы определить объект внимания мамы, ребенок должен был реконструировать ее точку зрения и сопоставить с информацией, доступной с его собственной позиции («мама не знает о четвертой игрушке»). В терминах теории концептуальной интеграции Ж. Фоконье и М. Тернера (Fauconnier, Turner, 2002) ребенок выполняет операцию интеграции (blending) разных ментальных пространств (mental spaces), отражающих его позицию и точку зрения наблюдаемого человека («мама видела, что...»). Возникающее в результате интегрированное пространство (blended space) включает объекты/референты, одновременно индексированные в двух разных пространствах («игрушка новая для мамы» / «мама не видела игрушку»), что обеспечивает возможность выделения потенциальных объектов внимания другого человека.
Таким образом, проведенный анализ литературных данных показывает, что идентификация объектов зрительного внимания другого человека основывается на трех основных источниках информации. Во-первых, это перцептивная информация об ориентации позы, головы и ориентации глаз наблюдаемого человека, которая может обрабатываться с разной степенью детализации (требующей разных временных и ресурсных затрат) и позволяет с большей или меньшей точностью экстраполировать линию его взгляда. Во-вторых, это низкоуровневая информация о «заметных» (salient) объектах, присутствующих в зоне взгляда наблюдаемого человека. В-третьих, это высокоуровневая информация о потенциальных объектах внимания индивида, «вычисляемая» в результате реконструкции перспективы2 (Термин «перспектива» используется в широком значении как позиция наблюдателя или точка зрения, которой придерживается наблюдатель, интерпретируя объекты и события (Ирисханова, 2014).) наблюдаемого человека (perspective-taking, напр.: Epley, Caruso, 2008) и ее сопоставления с информацией, доступной с позиции наблюдателя.
Как взаимодействуют процессы анализа призна- ков направления взгляда (gaze direction cues), восходящей (bottom-up) и нисходящей (top-down) обработки информации при идентификации объектов внимания наблюдаемых участников реальных коммуникативных ситуаций? Какому из указанных источников информации отдается приоритет в ситуациях конфликта, например, когда прогнозируемый объект внимания характеризуется малым размером, низким уровнем «визуальной яркости» и находится среди множества «ярких» объектов? С целью ответа на эти вопросы был проведен первый эксперимент.
Эксперимент 1
Испытуемые
В эксперименте приняли участие 74 здоровых испытуемых обоих полов в возрасте от 19 до 37 лет, которые были разделены на первую (N = 18), вторую (N=18), третью (N = 21) и четвертую (N=17) экспериментальные группы.
Дизайн и процедура эксперимента
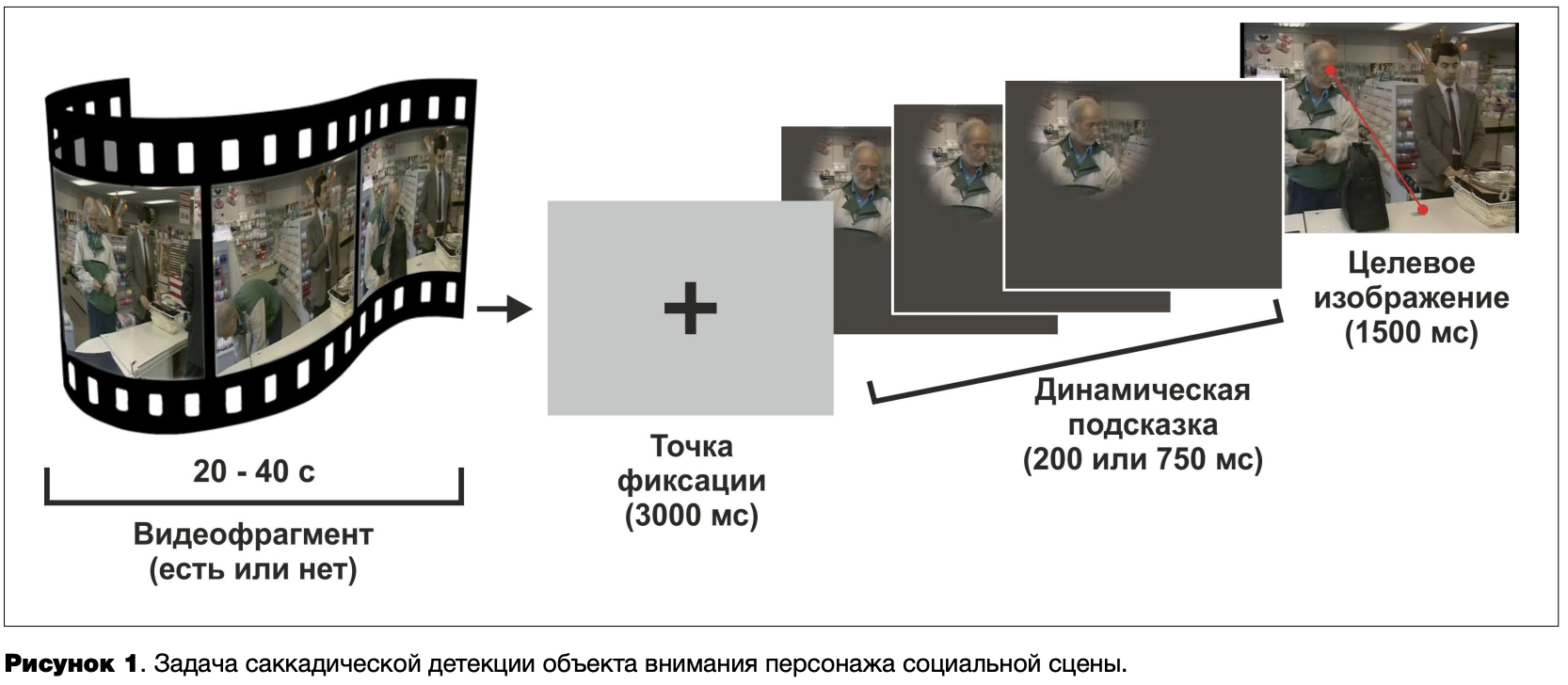
Для исследования процессов совместного внимания была разработана экспериментальная процедура, представляющая собой сочетание задачи саккадической детекции (saccadic detection task) (Crouzet et al., 2010) и методики «подсказки взглядом» (gaze-cueing paradigm) (Friesen, Kingstone, 1998). Поскольку динамические стимулы по сравнению со статическими позволяют более эффективно отслеживать направление взгляда (Risko et al., 2012), в качестве «подсказки» испытуемым последовательно предъявлялись пять кадров, создающие впечатление поворота головы персонажа в ту или иную сторону. Объектом саккадической детекции являлся предмет, на который направлен взгляд персонажа. Процедура эксперимента представлена на рисунке 1.
При отсутствии какой-либо предварительной информации или сразу после просмотра видеофрагмента, позволяющего сформировать представление о контексте коммуникативной ситуации, испытуемые выполняли задачу саккадической детекции объекта внимания одного из персонажей. После фиксации взгляда в центре экрана им предъявлялась динамическая «подсказка», длительность экспозиции которой составляла 200 или 750 мс. Затем в течение 1500 мс предъявлялось целевое изображение — кадр сцены, ранее не виденный испытуемым. Задача испытуемого состояла в том, чтобы как можно быстрее перевести взгляд на объект, на который, по его мнению, смотрит персонаж. Другими словами, испытуемый должен был совершить саккаду от области лица персонажа к предполагаемому объекту его внимания. После окончания пробы он должен был назвать вслух данный объект.
Перед началом эксперимента все испытуемые выполняли тренировочное задание. Затем четыре группы испытуемых выполняли задачу в одном из условий: (1)наличие или отсутствие информации о контексте коммуникации; (2) короткое или длительное время экспозиции информации, предоставляемой для визуальной оценки направления взгляда персонажа. Анализировались вербальные ответы испытуемых, локализация их зрительных фиксаций, угол отклонения первой саккады от линии взгляда персонажа, оцениваемой по объективным характеристикам изображения (то есть по ориентации позы, головы и глаз изображенного человека), а также время поиска объекта внимания персонажа, рассматриваемое как промежуток времени от момента предъявления целевого изображения до первой фиксации на целевом объекте.
Оборудование и стимульный материал
Стимулы предъявлялись на 19-дюймовом цветном ЖК мониторе с разрешением 1280x1024 точек. Расстояние от экрана до глаз испытуемого составляло 60 см. Угловые размеры предъявляемых видеофрагментов и кадров сцен составляли 25°х18°. Угловые размеры целевых стимулов (объектов внимания наблюдаемых персонажей) варьировали от 0.2° до 1.5°. Запись движений глаз осуществлялась при помощи системы регистрации движений глаз Tobii Х120 (Tobii Technology, Швеция) с частотой 120 Гц (пространственное разрешение 0.3°). Перед выполнением каждой пробы испытуемый проходил процедуру калибровки. Распознавание зрительных фиксаций и саккад осуществлялось с помощью алгоритма «І-НММ» (Komogortsev et al., 2010). Из анализа были исключены данные трех испытуемых, записи движений глаз которых оказались невалидными.
В качестве стимульного материала использовались пять видеофрагментов социальных ситуаций из телесериала «Мистер Бин» (Великобритания, 1990-95), художественных фильмов «Новые времена» (США, 1936), «Собачья жизнь» (США, 1918) и «Пугало» (США, 1920) длительностью от 20 до 40 с.
Ситуация № 1 (телесериал «Мистер Бин»). У кассы супермаркета стоят два покупателя: пожилой мужчина и Мистер Бин. Мужчина отдает продавцу скидочную карту, в то время как Мистер Бин достает аналогичную карту и демонстрирует ее зрителю. Продавец возвращает мужчине скидочную карту (кладет ее перед ним на прилавок), но последний не замечает этого. Мистер Бин кладет свою карту на прилавок рядом с картой мужчины. Не замечая своей карты, покупатель ставит на нее сумку. Видеоклип прерывается в тот момент, когда мужчина делает начальное движение по направлению к прилавку; и зритель ожидает, что вместо своей карты он ошибочно возьмет карту Мистера Бина. Задача: основываясь на оценке поворота головы покупателя, определить объект его внимания.
Ситуация №2 (фильм «Новые времена»). Маленький бродяга (Ч. Чаплин) помогает мастеру чинить заводской пресс. Мастер просит его подержать инструмент и пиджак. Не подумав, бродяга кладет их под пресс. Когда мастер включает пресс, герой успевает выхватить из-под него инструмент, но забывает про пиджак. Пресс опускается. Видеоклип прерывается в тот момент, когда пресс поднимается; и зритель ожидает, что оба персонажа увидят испорченный пиджак мастера. Задача: основываясь на оценке поворота головы героя Ч. Чаплина, определить объект его внимания.
Ситуация №3 (фильм «Собачья жизнь»). Маленький бродяга (Ч. Чаплин) замечает стоящего за забором торговца сосисками. Просунув руку через щель в заборе, бродяга ворует сосиску и готовится ее съесть. Проходящий мимо полицейский замечает факт воровства и останавливается, наблюдая через забор за действиями бродяги. Видеоклип прерывается в тот момент, когда бродяга начинает поворачивать лицо к забору; и зритель ожидает, что он заметит полицейского. Задача: основываясь на оценке поворота головы бродяги, определить объект его внимания.
Ситуация №4 (фильм «Пугало»). У одного из братьев (Б. Китон) болит зуб. Второй брат предлагает ему его вырвать. Один конец веревки он привязывает к больному зубу героя Б. Китона, второй конец — к ручке двери. Затем он выходит из дома и становится по другую сторону двери, в то время как персонаж Б. Китона с привязанным зубом находится внутри дома у внутренней стороны двери. Второй брат резко открывает дверь от себя. Дверь бьет персонажа Б. Китона по лицу, но не вырывает его зуб. Раздосадованный, герой Б. Китона вскакивает и со злостью пинает
дверь ногой. Дверь закрывается, привязанная к ней веревка натягивается и, неожиданно для героя, вырывает его зуб. Видеоклип прерывается в тот момент, когда герой Б. Китона прижимает руку ко рту, пытаясь понять, что случилось с его зубом; и зритель ожидает, что оба персонажа посмотрят на лежащий у двери зуб. Задача: основываясь на оценке поворота головы персонажа Б. Китона, определить объект его внимания.
Ситуация №5 (телесериал «Мистер Бин»). Мистер Бин устанавливает новый телевизор. Он берет вилку от телевизора и втыкает ее в розетку, не замечая отсутствие провода, соединяющего вилку с телевизором. Затем персонаж пытается включить телевизор. Телевизор не включается. Персонаж стучит по телевизору. Видеоклип прерывается в тот момент, когда Мистер Бин поднимает голову; и зритель ожидает, что он увидит отсутствие провода у вилки. Задача: основываясь на оценке поворота головы Мистера Бина, определить объект его внимания.
Использованные в эксперименте видеофрагменты предъявлялись без звукового сопровождения и обладали следующими характеристиками:
- Содержание видеофрагментов и характеристики целевых стимулов исключали использование испытуемыми «восходящей» формы совместного внимания (bottom-up joint attention). В видеофрагментах отсутствовали явные признаки движения целевых объектов (будущих объектов внимания персонажей), могущие привлечь к ним непроизвольное внимание наблюдателей. Также в видеофрагментах отсутствовали пространственные подсказки, такие как повороты головы и указательные жесты персонажей, ориентирующие внимание наблюдателей в направлении целевых объектов.
- Видеофрагменты прерывались до начала поворота головы персонажа к объекту его интереса. Момент прерывания видеофрагментов всегда являлся неожиданным для испытуемых.
- В видеофрагментах № 1, № 2 и №4 целевые объекты внимания персонажа были связаны с интенциями обоих участников и являлись потенциальными референтами их предполагаемого взаимодействия. В видеофрагментах № 3 и № 5 целевые объекты были связаны с интенциями центрального персонажа.
Предъявляемые в качестве целевых изображений (рисунок 1) статичные кадры сцен3 (Под термином «сцена» здесь и далее подразумевается содержание отдельного кадра, предъявляемого в задаче поиска объекта внимания персонажа) характеризовались следующими характеристиками:
- Кадры отсутствовали в видеофрагментах и изображали персонажа, завершившего поворот головы к целевому объекту и фиксирующего на нем взгляд. Угловое расстояние от глаз персонажа до целевого объекта его внимания варьировало от 6.2° до 16.5°. По сравнению с видеофрагментами целевые объекты на кадрах были изображены со смещенного ракурса (ситуации №3 и 5) или имели другой вид (ситуации №2 и 4).
- На всех кадрах целевые объекты внимания персонажей обладали маленьким размером (до 1.5°), низким уровнем «визуальной яркости» и были представлены в сложном окружении среди «ярких» объектов. Выделение «визуально ярких» областей кадров проводилось с помощью инструментария «Saliency Toolbox» (Walther, Koch, 2006).
- На линии взгляда персонажей находился только один объект. Линия взгляда изображенных на кадрах персонажей рассчитывалась по признакам ориентации их позы, головы и глаз. Оценивалось отклонение саккад испытуемых относительно данной линии.
Результаты и их обсуждение
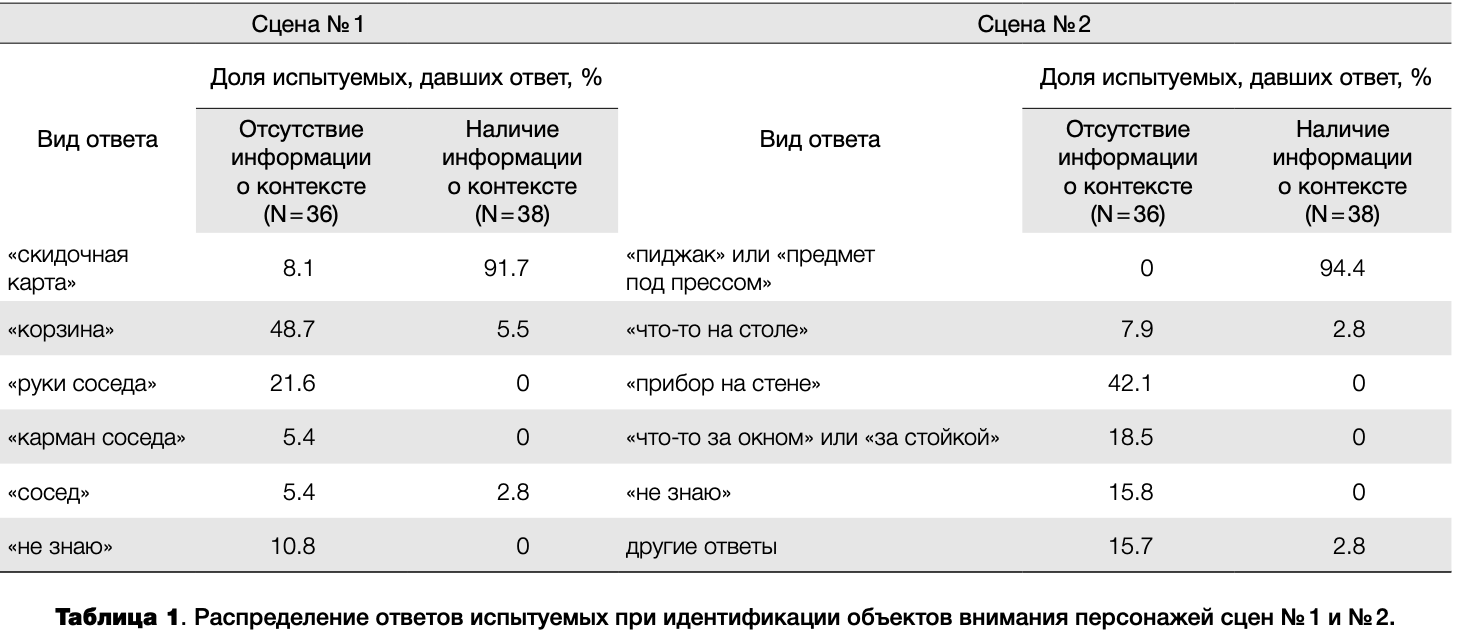
Были проанализированы вербальные ответы испытуемых при идентификации объектов внимания персонажей социальных сцен. Распределение ответов испытуемых для сцен № 1 и №2 представлено в таблице 1.
Как видно из представленных данных, наличие или отсутствие информации о контексте коммуникативной ситуации оказывало существенное влияние на ответы испытуемых. В сцене № 1 48.7% испытуемых, не обладавших информацией о контексте, указали на «корзину», и лишь 8.1% — на «скидочную карту», находящуюся на линии взгляда персонажа. Эти лица демонстрировали большое разнообразие вербальных ответов, обозначая карту как «купюра», «что- то на столе» и т. д., в связи с чем их ответы группировались на основе общности референта. В отличие от них, 91.7% испытуемых, обладавших информацией о контексте, указали на «скидочную карту» и лишь 5.5% — на «корзину». Сходные результаты были получены по остальным сценам.
На рисунке 2 показано распределение фиксаций взгляда испытуемых при поиске объектов внимания персонажей социальных сцен.
Как видно из представленных данных, наличие информации о коммуникативном контексте оказывает существенное влияние на зрительный поиск объектов внимания наблюдаемых персонажей. Испытуемые, не просмотревшие видеофрагменты, совершали саккады в зоне взгляда персонажей, но испытывали выраженные затруднения в идентификации объектов их внимания, демонстрируя хаотичную и разнонаправленную поисковую активность и фиксируя взглядом преимущественно «визуально яркие» объекты. Напротив, лица, просмотревшие видеофрагменты, решали поставленную задачу путем реализации одной или двух точных саккад от лица персонажа к объекту его внимания. Они демонстрировали эффективный вид совместного внимания, предполагавший быстрое экстрафовеальное выделение объектов взгляда персонажей и реализацию к ним саккад, несмотря на малый размер, низкий уровень «визуальной яркости» этих объектов и наличие конкурирующего предметного окружения.
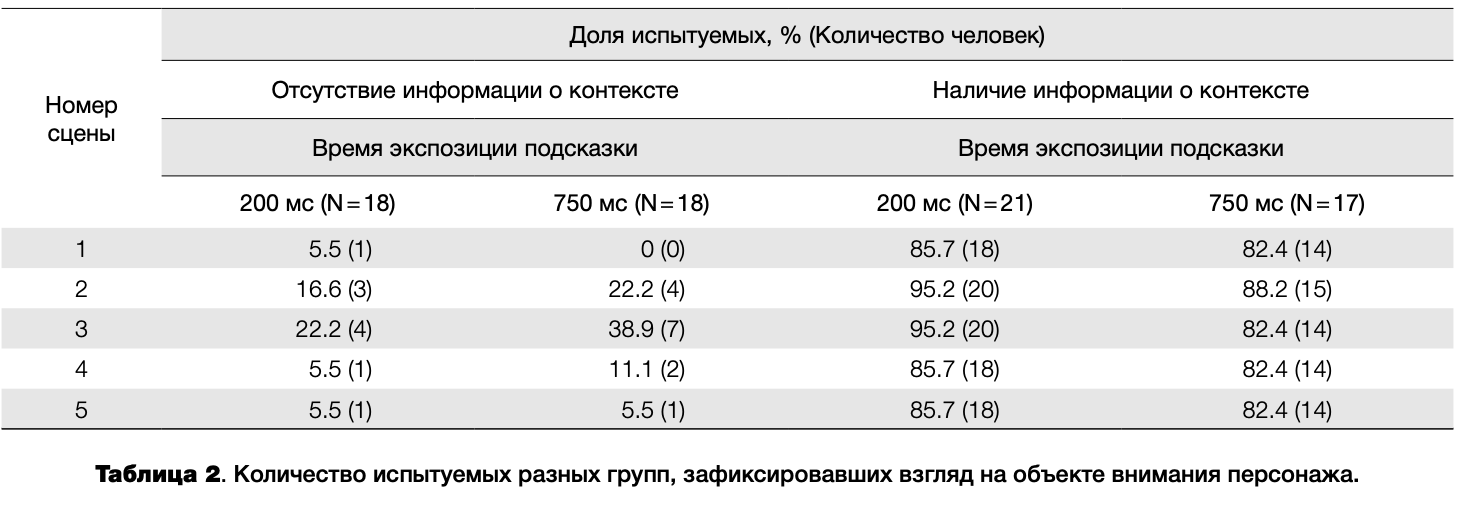
В таблице 2 представлены данные о количестве испытуемых разных групп, зафиксировавших взгляд на области целевого объекта (обозначенной красным прямоугольником на рисунке 2).
Для показателя количества зрительных фиксаций на области целевого объекта, суммированного по пяти сценам, проведен дисперсионный анализ (ANOVA) с двумя межгрупповыми факторами — Информация о контексте (нет/есть) и Время экспозиции подсказки (200/750 мс). Выявлено достоверное влияние на данный показатель фактора Информация о контексте (F (1, 70)= 439; р<.001, Г|2 = .862), в то время как влияние фактора Время экспозиции подсказки (F (1, 70) = 0.05; р = .8, Г|2 = .001) и взаимодействия обоих факторов (F (1, 70) = 2.2; р = .14, г|2 = .О31) оказалось не значимым.

Дальнейший анализ показал, что улиц, обладавших информацией о контексте коммуникативной ситуации и сформировавших догадки относительно потенциальных объектов внимания персонажей, фактор Номер сцены не оказывает значимого влияния на успешность саккадической детекции объекта внимания персонажа (Cochran’s Q= 1.8, р = .76). Как видно из данных таблицы 2, в 82-95% случаев эти лица эффективно реализовали саккады к целевым объектам, независимо от структурных характеристик визуальной сцены (наличие «визуально ярких» дистракторов, размер и характеристики целевых объектов, их удаленность от глаз персонажа и т. д.) и степени доступности перцептивной информации об ориентации головы и глаз персонажа.

У лиц, не обладавших информацией о коммуникативном контексте, фактор Номер сцены значимо влиял на успешность саккадической детекции целевых объектов (Cochran’s Q=16.3, р-.ООЗ). Данные таблицы 2 показывают, что эти испытуемые чаще находили взглядом целевой объект в сцене № 3 по сравнению с остальными сценами. Это объясняется тем, что в сцене №3 в качестве объекта внимания персонажа выступало лицо человека, являющееся биологически значимым стимулом, обладающим свойством «заметности» (saliency) для испытуемых (например: Cerf et al., 2009). Этот факт, а также данные рисунка 2 позволяют предположить, что у лиц, не просмотревших видеофрагменты и, таким образом, не имевших догадок о целевых объектах, совместное внимание направлялось преимущественно «заметными» стимулами, находящимися в зоне взгляда наблюдаемого персонажа. На рисунке 3 показано распределение зрительных фиксаций испытуемых, не просматривавших видеофрагменты, в сопоставлении с «визуально яркими» областями изображения, выделенными с помощью инструментария «Saliency Toolbox» (Walther, Koch, 2006).
Представленные данные показывают, что испытуемые чаще фиксируют внимание на находящихся в зоне взгляда наблюдаемого человека биологических объектах (лицо Мистера Бина в сцене №1; лицо полицейского в сцене № 3), а также «визуально ярких» объектах (прибор — в сцене №2; часы — в сцене №5), независимо от степени их близости к линии взгляда персонажа. Эти результаты согласуются с данными описанного выше эксперимента А. Боржи с соавт. (Borji et al., 2014) и свидетельствуют о том, что механизм экстраполяции линии взгляда, постулируемый Дж. Баттеруортом и другими авторами, не работает в коммуникативных ситуациях. Как правило, люди не выполняют детализированный анализ признаков ориентации головы и глаз другого человека с целью мысленного «вычерчивания» линии его взгляда и определения расположенного на конце этой линии объекта внимания. Подобный анализ требует значительных ресурсов фокальной обработки и временных затрат, в связи с чем является неэффективным (он также оказался неэффективным в робототехнике, например, Yucel et al., 2013). Вместо этого люди осуществляют быструю приблизительную оценку ориентации головы и глаз наблюдаемого человека, позволяющую выделить зону его взгляда, а затем идентифицируют попадающие в эту зону «визуально яркие» и биологически значимые объекты.
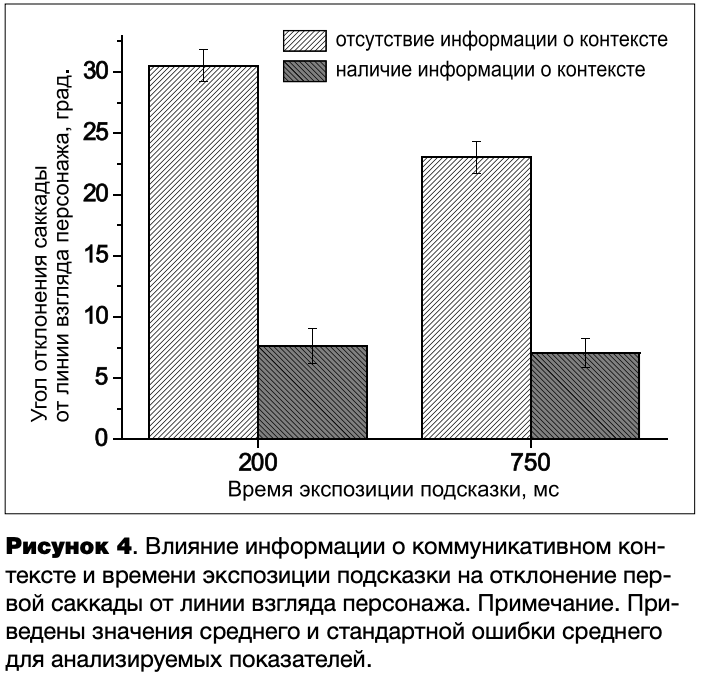
Можно предположить, что, в зависимости от доступности признаков ориентации головы и глаз наблюдаемого человека, ширина выделяемой зоны взгляда (угол вершины конуса) будет различной. Для проверки этого предположения у лиц, не обладавших информацией о коммуникативном контексте, проанализирован показатель отклонения первых саккад от линии взгляда персонажа, для которого был проведен дисперсионный анализ (ANOVA) с межгрупповым фактором Время экспозиции подсказки (200/750 мс) и внутригрупповым фактором Номер сцены (сцены 1, 2, 3, 4, 5). Выявлено достоверное влияние на данный показатель как фактора Время экспозиции подсказки (Л(1,34) = 17.2; р<.001, г|2 = .33б), так и фактора Номер сцены (F (4,31)^88.3; р<.001, г|2 = .919), в то время как их взаимодействие оказалось не значимым (F (4,31) = 1.8; р = .14, г|2 = ,194). Лица, которым предоставлялось меньшее время для оценки признаков ориентации головы и глаз персонажа, обнаруживали большее отклонение первых саккад от линии взгляда наблюдаемого человека по сравнению с испытуемыми, которым предоставлялось большее время для оценки данных признаков. Это свидетельствует, что возрастание доступности информации о признаках ориентации головы и глаз наблюдаемого персонажа приводит к сужению выделяемой зоны взгляда, в которой осуществляется поиск объектов его внимания.

Для фактора Номер сцены проведено попарное сравнение средних, которое показало, что в сценах № 1, № 2 и № 3, где «визуально яркие» дистракторы находятся на значительном отдалении от линии взгляда персонажа, испытуемые обнаруживают достоверно больший угол отклонения саккад, чем в сценах №4 и №5, где дистракторы находятся на небольшом отдалении от линии взгляда.
Показатель отклонения саккад от линии взгляда персонажа также был проанализирован у лиц, просмотревших видеофрагменты. Дисперсионный анализ не выявил значимого влияния на данный показатель факторов Время экспозиции подсказки (Р (1, 36) = 1.0; р = .3, г]2 = .028) и Номер сцены (Р (4, 33) =0.8; р = .5, г]2 = .090) (рисунок 4).
Выявленные факты отсутствия влияния структурных характеристик сцены и времени экспозиции подсказки на саккадические реакции испытуемых, просмотревших видеофрагменты социальных ситуаций, согласуются с данными на рисунке 2 и свидетельствуют о том, что совместное внимание данных лиц детерминируется преимущественно нисходящими (top-down) факторами, в то время как восходящие (bottom-up) факторы и доступность информации о направлении взгляда персонажа не играют существенной роли.
У испытуемых, просмотревших видеофрагменты ситуаций, также было проанализировано время зрительного поиска целевого объекта внимания персонажа, то есть промежуток времени от момента предъявления кадра сцены до первой фиксации на целевом объекте. Дисперсионный анализ не выявил значимого влияния на этот показатель фактора Время экспозиции подсказки (F(l, 36) = 0.2; р = .6, г]2 = .005), но показал достоверное влияние фактора Номер сцены (Р (4,33) = 18.7; р < .001, г]2 = .694). Взаимодействие этих факторов оказалось не значимым (F (4, 33) = 1.8; р = . 13, г]2 = .186). Проведенный для фактора Номер сцены анализ попарных сравнений показал, что у лиц, просмотревших видеофрагменты, время поиска объекта внимания персонажа определялось исключительно удаленностью данного объекта от головы и глаз изображенного человека (то есть исходной точки, от которой испытуемые начинали зрительный поиск). Оно являлось небольшим для сцен № 2 и № 3, где угловое расстояние от глаз персонажа до целевого объекта составляло 6.2° и 7.5° (соответственно, 0.47 ±0.17 с. и 0.53 ±0.23 с.) и достоверно большим для сцен №1, №4 и №5, где данное расстояние составляло 14.5°, 14.6° и 16.5° (соответственно, 0.67 ±0.17 с., 0.74 ±0.18 с. и 0.78 ±0.23 с.). Другими словами, у лиц, обладавших информацией о коммуникативном контексте, время поиска объектов внимания персонажей не зависело от визуальных характеристик этих объектов и структурных особенностей сцены (цветовая гамма, компоновка сцены, наличие и расположение «визуально ярких» дистракторов и т. д.) и определялось исключительно расстоянием, на которое испытуемым было необходимо переместить свой взгляд.
При объяснении вышеописанных фактов необходимо учесть три обстоятельства. Во-первых, как отмечалось ранее, испытуемые осуществляли поиск объектов внимания персонажей в ранее не виденных ими кадрах сцен. В предъявленных им видеофрагментах эти объекты были изображены со смещенного ракурса или имели другой вид. Во-вторых, видеофрагменты всегда прерывались неожиданно для испытуемых, и они не могли заранее предугадать, какие именно объекты внимания персонажей им предстоит искать. В-третьих, в видеофрагментах отсутствовали пространственные подсказки, такие как повороты головы и указательные жесты, ориентирующие внимание испытуемых в направлении будущих объектов внимания персонажей. Возникает вопрос: каким образом испытуемым, просмотревшим видеофрагменты, удавалось осуществлять столь точную саккадическую детекцию объектов внимания персонажей в ранее не виденных кадрах сцены в условиях визуальной «малозаметности» (non-saliency) и малого размера этих объектов, а также присутствия конкурирующих «ярких» дистракторов?
Согласно данным исследований (например, Malcolm, Henderson, 2009), столь эффективный зрительный поиск мог основываться только на предварительно известной информации о характеристиках целевых объектов. С учетом факта, что испытуемые заранее не знали, какие объекты им предстоит искать, можно сделать вывод о том, что при восприятии социальной ситуации они избирательно запоминали информацию о характеристиках тех стимулов, которые рассматривались как объекты будущего внимания персонажей и/или референты их предполагаемого коммуникативного взаимодействия. Однако каким образом осуществлялось выделение этих стимулов?
Для выделения будущих объектов внимания персонажей было недостаточно знаний о ситуации и понимания намерений ее участников. Необходимо было рассмотрение ситуации одновременно с нескольких точек зрения. Например, чтобы определить будущий объект внимания покупателя в сцене № 1 (см. выше), наблюдатель должен был предварительно не только распознать его намерение взять карту, но и спрогнозировать ошибку персонажа, вследствие которой он принял чужую карту за свою. Для этого требовалось сопоставить точку зрения покупателя с информацией, доступной с позиции наблюдателя (мужчина не заметил, как положил сумку на свою карту). Чтобы определить будущий объект внимания Маленького бродяги в сцене № 2, наблюдатель должен был предварительно заметить его ошибку, когда бродяга оставил пиджак под прессом. Это также достигалось сопоставлением точки зрения персонажа с информацией, доступной с позиции наблюдателя. Чтобы определить будущий объект внимания персонажа в сцене № 3, наблюдатель также должен был реконструировать его точку зрения и сопоставить с информацией, доступной с внешней позиции (бродяга не заметил полицейского, когда воровал сосиску). Итак, успешная идентификация объектов внимания участников коммуникативных ситуаций требовала реконструкции точек зрения персонажей и сопоставления их с информацией, доступной с внешней позиции.
Можно предположить, что при восприятии видеофрагментов процессы концептуализации социальной ситуации, реконструкции и сопоставления точек зрения ее участников осуществлялись испытуемыми очень быстро, в режиме реального времени. По результатам такого анализа выделялись потенциальные объекты внимания и/или референты коммуникативного взаимодействия участников, информация о характеристиках которых направлялась в рабочую память наблюдателя и в дальнейшем оказывала нисходящее влияние на зрительный поиск объектов взгляда персонажей в кадрах сцен.
Существующие в настоящее время экспериментальные данные свидетельствуют о наличии двух видов нисходящей (top-down) информации, позволяющих осуществлять эффективный зрительный поиск «малозаметных» объектов в реалистичном окружении. Во-первых, это информация о визуальных признаках цели (target template information). Во-вторых, это информация о локализации цели в структуре визуальной сцены (scene context information) (Malcolm, Henderson, 2010). Какой из этих видов информации преимущественно используется при поиске объектов внимания персонажей социальных ситуаций? Для ответа на этот вопрос был проведен второй эксперимент.
Эксперимент 2
Испытуемые
В эксперименте приняли участие 35 здоровых испытуемых обоего пола в возрасте от 18 до 32 лет, которые были разделены на первую (N = 15), вторую (N = 10) и третью (N = 10) экспериментальные группы.


Дизайн и процедура эксперимента
Использовался методический подход, основанный на изменении предъявляемой зрительной информации в зависимости от регистрируемой в реальном времени фиксации взора испытуемого (gaze-contingent paradigm). Применялась процедура «движущегося окна» (moving window paradigm), предполагающая, что только часть изображения в пределах фиксации взора предъявляется нормальным образом («окно ясного видения»), в то время как остальные части изображения (периферическая информация) скрыты от испытуемого или предъявляются в искаженном виде.
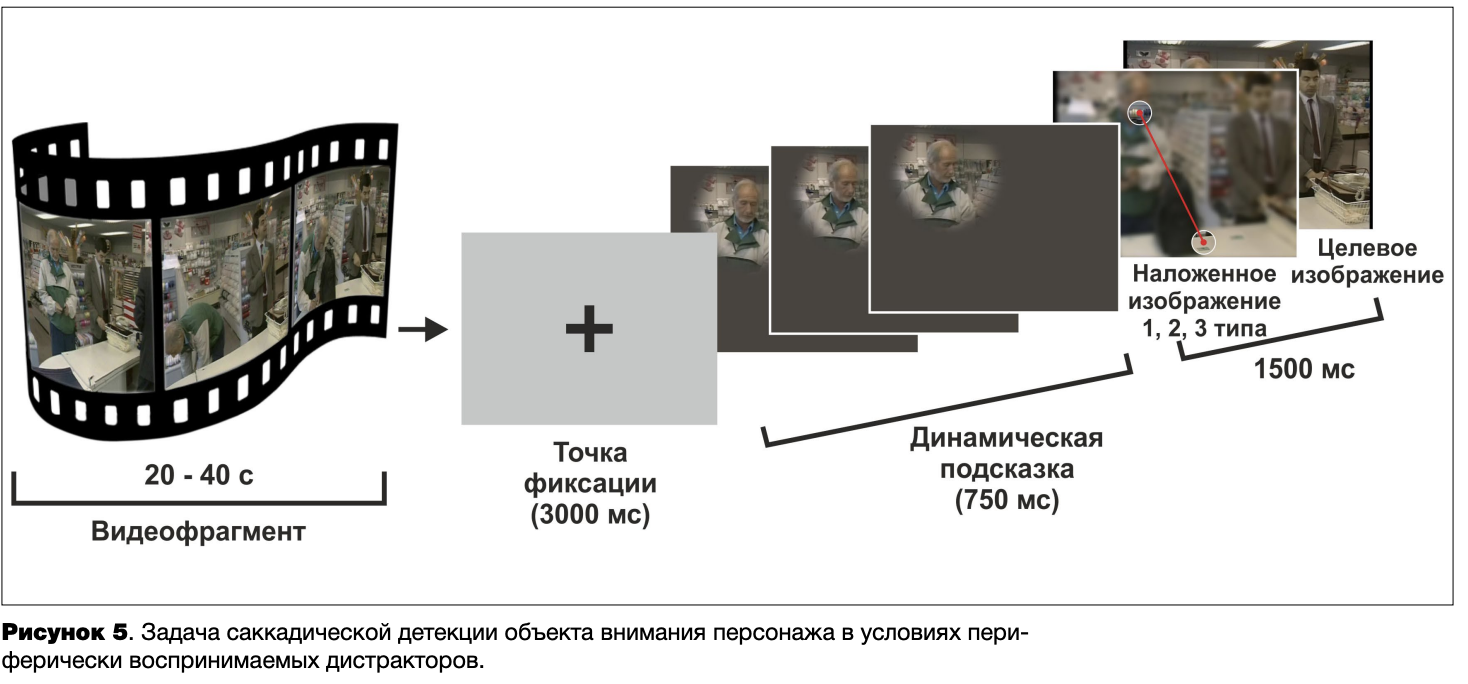
Разработанная нами ранее модификация этой процедуры состояла в следующем. Испытуемому предъявляются два наложенных друг на друга изображения: верхнее А1 и нижнее А2. В области фиксации взгляда испытуемого, регистрируемой и распознаваемой в режиме реального времени, возникает окно, диаметр которого составляет 2°. Данное окно представляет собой «дырку» в верхнем изображении А1, через которую виден фрагмент расположенного под ним изображения А2. Другими словами, в фокальной области испытуемому предъявляется фрагмент А2, в периферической области — изображение А1. Когда испытуемый совершает саккаду и фиксирует взгляд на новом участке изображения А1, эта фиксация распознается в течение 15-20 мс, и на данном участке появляется новая «дырка», через которую виден уже другой фрагмент изображения А2. Варьирование разных типов дис- тракторов на изображении А1 позволяет исследовать нисходящее влияние информации в зрительной памяти на выбор саккадических целей. В типичной задаче испытуемому предлагается быстро переместить взгляд (и движущееся вместе с ним окно) к запомненной ранее области локализации целевого стимула, игнорируя дистракторы на изображении А1. За счет фокальной обработки видимой в окне информации (виден / не виден целевой стимул) он получает прямую обратную связь об успешности выполнения задания (Зотов, Андрианова, 2014). Экспериментальная процедура, использованная в настоящем исследовании, представлена на рисунке 5.
Как и в первом исследовании, испытуемым предлагалась задача поиска объекта внимания персонажа. Непосредственно перед выполнением данной задачи все испытуемые просматривали идентичные видеофрагменты, позволяющие сформировать представление о контексте коммуникативной ситуации. Задача начиналась с фиксации взгляда в центре экрана, после чего испытуемому предъявлялась «подсказка» — динамическое изображение головы персонажа, поворачивающейся в ту или иную сторону. Затем появлялось «размытое» (с помощью низкочастотного фильтра) изображение А1, под которым находилось целевое изображение А2. На изображении А1 присутствовал дис- трактор, сходный с целевым объектом, но смещенный относительно него на 9-11°. На месте фиксации взгляда испытуемого возникало окно диаметром 2°, через которое он видел фрагмент изображения А2. Задача испытуемого состояла в том, чтобы как можно быстрее перевести взгляд к запомненному ранее местоположению объекта внимания персонажа, игнорируя дис- трактор на изображении А1. Всем испытуемым говорилось, что расположение дистрактора в 100% случаев не соответствует расположению целевого объекта, поэтому они не должны фиксировать на нем взгляд.
Использовались три типа наложенных изображений: 1 тип — изображение дистрактора, идентичного целевому объекту по визуальным признакам, в контексте той же сцены; 2 тип — изображение дистрактора, отличающегося от целевого объекта по цветовым характеристикам, в контексте той же сцены; 3 тип — изображение дистрактора, идентичного целевому объекту по визуальным признакам, в контексте другой сцены (рисунок 6). Три группы испытуемых выполняли одинаковые задачи с разными типами наложенных изображений А1.
Оборудование и стимульный материал
Оборудование, условия обследования испытуемых и алгоритмы анализа данных движений глаз были такими же, что и в предыдущем эксперименте. В качестве стимульного материала использовались кадры и видеофрагменты двух социальных ситуаций, первая из которых была идентичной ситуации № 1 первого эксперимента, вторая представляла собой социальную ситуацию из художественного фильма «Собачья жизнь» (США, 1918).
Результаты и их обсуждение
Несмотря на эксплицитное знание о нерелевантности дистракторов, ошибочные фиксации на них в среднем обнаружили 93% испытуемых, которым предъявлялись наложенные изображения типа 1, 81% испытуемых, которым предъявлялись наложенные изображения типа 2, и 15 % испытуемых, которым предъявлялись наложенные изображения типа 3. На рисунке 7 показано распределение фиксаций взгляда при детекции объектов внимания персонажей в разных группах испытуемых.
Как видно из рисунка 7, дистракторы типа 1, идентичные целевым объектам по визуальным признакам и предъявленные в том же контексте, вызывают наибольшее количество ошибочных фиксаций испытуемых. Дистракторы типа 3, предъявленные в контексте другой сцены, вызывают наименьшее количество ошибочных фиксаций. Видно, что во второй сцене дистрактор типа 1 вызывает значительное количество ошибочных фиксаций, несмотря на то, что он находится на значительном отдалении от линии взгляда участника сцены. Это показывает, что при детекции объекта внимания персонажа испытуемые в большей степени опираются на признаки экстрафовеально воспринимаемых стимулов и их соответствие удерживаемой в памяти информации, чем на анализ положения головы человека, позволяющий экстраполировать линию его взгляда.
По данным субъективных отчетов, все испытуемые, которым предъявлялись дистракторы типа 3, мгновенно распознавали изменение визуального контекста сцены (gist of scene), что соответствует данным зарубежных исследований (Oliva, Torralba, 2005). На нескольких испытуемых неожиданное изменение контекста оказало дезорганизующий эффект: они реализовали саккады к лицам персонажей новой сцены, забыв о задаче детекции целевого объекта. Данные этих испытуемых были исключены из анализа.
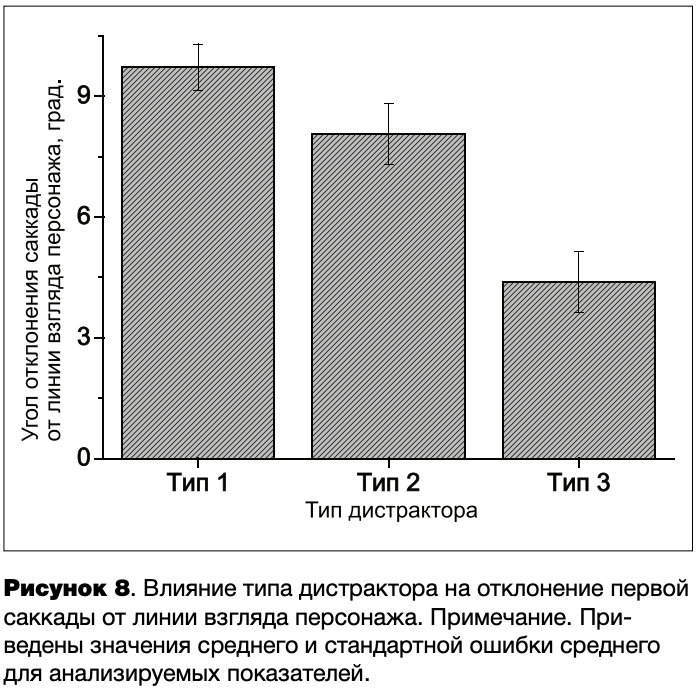
Для показателя отклонения первых саккад от линии взгляда персонажа был проведен дисперсионный анализ (ANOVA) с одним межгрупповым фактором Тип дистрактора (тип 1,2,3) и одним внутригрупповым фактором Номер сцены (сцены 1 и 2). Выявлено достоверное влияние на данный показатель фактора Тип дистрактора (F (2,32) = 18.4;р< .001, г]2 = .535), в то время как влияние фактора Номер сцены оказалось статистически не значимым (F (1, 32) = 2.1; р = .1, г]2 = .062) (рисунок 7). Анализ парных сравнений показал, что показатель отклонения саккад значимо не различается у лиц, которым предъявлялись дистракторы типов 1 и 2 (р = .24), но имеет достоверно меньшие значения (р < .001) у лиц, которым предъявлялись дистракторы типа 3 (рисунок 8).
Результаты настоящего эксперимента показывают, что при восприятии невербальных коммуникативных сцен наблюдатели выделяют потенциальные объекты внимания персонажей и поддерживают в рабочей памяти информацию об их визуальных признаках и относительной локализации в пространстве сцены. Экстрафовеальные стимулы, в наибольшей степени соответствующие этой информации, «захватывают» внимание испытуемых и выбираются в качестве саккадических целей, несмотря на эксплицитное знание об их нерелевантности.
Общее обсуждение результатов
Процессы совместного внимания связывают преимущественно со способностью человека прослеживать взором направление взора собеседника (gaze following) (например, Emery, 2000). Многие работы опираются на концепцию Дж. Баттеруорта, постулирующую, что идентификация объекта внимания другого человека основывается на визуальной оценке ориентации его головы и глаз, позволяющей экстраполировать линию его взгляда (Butterworth, Jarrett, 1991).
Между тем ориентация головы и глаз другого индивида является недостаточным источником информации об объекте его внимания. По направлению взгляда человека невозможно определить, на какой объект из множества расположенных рядом или на какие аспекты объекта он направил свое внимание.
Анализ литературных данных позволил выделить три вида информации, на которых основывается идентификация объектов зрительного внимания другого человека. Наряду с данными об ориентации головы и глаз, это низкоуровневая информация о присутствующих в сцене визуально «заметных» объектах и высокоуровневая информация о потенциальных объектах внимания наблюдаемого человека, «вычисляемая» на основе реконструкции его точки зрения. Цель настоящей работы состояла в анализе взаимодействия этих видов информации при идентификации объектов внимания участников невербальных коммуникативных сцен. Результаты проведенных экспериментов позволили сделать ряд выводов, касающихся механизмов как «восходящего», так и «нисходящего» совместного внимания.
«Восходящее» совместное внимание
Исследование показало, что лица, не обладающие информацией о контексте коммуникативной ситуации, демонстрируют совместное внимание, ведомое как информацией о признаках ориентации головы и глаз человека, так и «восходящей» (bottom-up) информацией о «визуально ярких» или биологически значимых объектах, попадающих в зону взгляда наблюдаемого персонажа и привлекающих непроизвольное внимание наблюдателя.
Результаты настоящего исследования оказались сходными с данными эксперимента А. Боржи с со- авт. (Boiji et al., 2014), показавшими, что визуально «яркие» элементы (saliency тар), находящиеся в зоне взгляда (gaze тар) изображенного человека, в первую очередь привлекают внимание испытуемых при свободном рассматривании фотографических изображений. Если в эксперименте А. Боржи перед испытуемыми не ставилось специальной задачи поиска объекта внимания изображенного человека, то в нашем исследовании такая задача ставилась. Следовательно, можно было ожидать, что наши испытуемые будут более точны в прослеживании линии взгляда персонажа и идентификации расположенного на конце этой линии объекта. Однако это ожидание не подтвердились. Как и испытуемые А. Боржи, наши испытуемые проводили быструю автоматизированную оценку ориентации головы и глаз наблюдаемого человека, позволяющую выделить относительно широкую (±15°) зону его взгляда, а затем фиксировали внимание на находящихся в этой зоне «визуально ярких» или биологически значимых объектах. Большая доступность информации об ориентации головы и глаз персонажа приводила к уменьшению зоны, в которой выбирался объект внимания.
Необходимо отметить, что продемонстрированная нашими испытуемыми стратегия совместного внимания является гораздо более эффективной по сравнению со стратегией экстраполяции линии взгляда, постулируемой Дж. Баттеруортом и другими авторами (Butterworth, Jarrett, 1991; Bock et al., 2008). Последняя предполагает, что индивид осуществляет детализированный анализ признаков ориентации головы и глаз наблюдаемого человека, на основе которого мысленно выстраивает линию его взгляда и идентифицирует расположенный на данной линии объект. Такая стратегия совместного внимания требует значительного времени и ресурсов фокальной обработки и, в связи с этим, является неэффективной в динамических коммуникативных ситуациях.
«Нисходящее» совместное внимание
Исследование показало, что совместное внимание лиц, обладающих информацией о коммуникативном контексте, направляется преимущественно «нисходящей» (top-down) информацией о потенциальных референтах коммуникации, в то время как «восходящая» (bottom- up) информация о «визуально ярких» объектах сцены и степень доступности признаков ориентации головы и глаз наблюдаемого человека не играют какой-либо существенной роли. В проведенном эксперименте испытуемые, сформировавшие представление о потенциальных объектах внимания участников коммуникации, продемонстрировали способность к практически мгновенному поиску таких объектов в пространстве зрительной сцены. Данная способность не зависела от перцептивных характеристик этих объектов (размер и уровень «визуальной яркости»), характеристик сцены (цветовая гамма, компоновка сцены, наличие и расположение «визуально ярких» дистракторов и т. д.), а также степени доступности информации об ориентации головы и глаз наблюдаемых персонажей.
Полученные результаты свидетельствуют о несостоятельности концепций, сводящих совместное внимание к элементарному и «рефлекторному» процессу отслеживания направления взгляда человека по ориентации его головы и глаз, и подтверждают выводы М. Томаселло и его коллег о ключевой роли «нисходящих» факторов в процессах совместного внимания человека (Томаселло, 2011; Moll et al., 2006).
Результаты исследования показывают, что при восприятии невербальных коммуникативных ситуаций наблюдатель быстро, в режиме реального времени, осуществляет концептуализацию наблюдаемых событий, реконструкцию и сопоставление точек зрения участников коммуникации. По результатам такого анализа выделяются потенциальные объекты внимания и/или референты коммуникативного взаимодействия участников, информацию о которых наблюдатель избирательно запоминает и поддерживает в рабочей памяти. В дальнейшем это позволяет ему легко идентифицировать референты взглядов, указательных жестов и дейктических высказываний наблюдаемых людей, а также осуществлять практически мгновенный поиск этих объектов/референтов в пространстве сцены.
Предложенный в настоящей работе экспериментальный подход может оказаться перспективным для изучения высокоуровневых механизмов зрительного внимания человека в целом. В большинстве исследований, посвященных роли «нисходящих» (top- down) факторов в процессах зрительного поиска, перед выполнением поисковой задачи испытуемым в той или иной форме предъявляется информация о целевом стимуле, который необходимо найти (например, Malcolm, Henderson, 2010). Между тем в повседневной жизни человек самостоятельно генерирует репрезентации целевых объектов поиска. Данное явление наиболее ярко представлено в ситуации просмотра кинофильма, когда наблюдатель ежесекундно обновляет репрезентации целевых объектов в памяти, каждый раз осуществляя поиск новых объектов в просматриваемых кадрах фильма. Какую информацию включают генерируемые наблюдателем репрезентации целевых объектов поиска? Требует ли формирование таких репрезентаций предварительной фокальной обработки целевого объекта? Каким образом происходит обновление (updating) репрезентаций целевых объектов в зрительной рабочей памяти наблюдателя? Пока эти вопросы остаются вне поля зрения исследователей. Результаты настоящей работы позволяют предположить, что такие репрезентации включают как информацию о низкоуровневых признаках целевых объектов (цвет, ориентация, размер), так и сведения об их относительной локализации в пространстве сцены, однако это предположение нуждается в дальнейшей экспериментальной проверке.
Роль реконструкции перспективы другого человека в процессах совместного внимания
Настоящая работа показала, что понимание контекста коммуникативной ситуации, определяющее успешность идентификации объектов внимания другого человека, предполагает создание и сопоставление разных точек зрения или перспектив. Этот вывод соответствует так называемой теории кругозора и окружения, разработанной выдающимся отечественным мыслителем М.М. Бахтиным еще в 20-х гг. прошлого века (Бахтин, 1979; 2010). По мнению М.М.Бахтина, жест, взгляд другого человека или, например, высказывание «так», взятые сами по себе, изолированно, не несут существенной информации и обретают значение лишь при соотнесении их с «внесловесным контекстом» коммуникативной ситуации. Этот «внесловесный контекст» складывается из трех компонентов: (1) общий для собеседников пространственный кругозор («вместе видимое»); (2) общие знания («вместе знаемое»); (3) согласующиеся концептуализации ситуации («согласно оцененное») (Бахтин, 2010, с. 152). Наблюдатель способен определить референты взглядов, жестов и высказываний лишь тогда, когда он «приобщится» к «общему пространственному и смысловому кругозору» участников коммуникации, то есть сконструирует и сопоставит их точки зрения на происходящее (там же). В качестве примера М.М.Бахтин приводит игру в разбойников: «Мальчик, играющий атамана разбойников, изнутри переживает свою жизнь разбойника, глазами разбойника смотрит на пробегающего мимо другого мальчика, его кругозор есть кругозор изображаемого им разбойника; то же самое имеет место и для его сотоварищей по игре» (Бахтин, 1979, с. 67). Жесты, взгляды и высказывания играющих детей зритель может понять лишь тогда, когда разделит с ними знание о разыгрываемом событии (нападение разбойников) и приобщится к их концептуальному видению внешнего окружения (палка — меч, столбы — солдаты). Одновременно зритель учитывает аспекты окружения, недоступные сознанию участников в данный момент времени, но релевантные их предполагаемым намерениям (автор обозначает это как принципиальный избыток видения зрителя по отношению к видению ситуации героем). Другими словами, происходит постоянное сопоставление («диалог») между тем, что видит / знает зритель, и тем, что, как он думает, видит / знает наблюдаемый персонаж. М. М. Бахтин пишет: «Близкой к действительной позиции зрителя представляется нам наивная установка того простолюдина, который предупреждал героя пьесы о сделанной против него засаде и готов был броситься ему на помощь во время сделанного на него нападения. Такой установкой наивный зритель занимал устойчивую позицию вне героя, учитывал трансгредиентные сознанию самого героя моменты» (там же, с. 71).
Вышеописанные положения теории М. М. Бахтина получили подтверждение в исследованиях последних лет, посвященных проблемам социального познания. В работах М. Томаселло было показано, что полиперспективные или диалогичные когнитивные репрезентации (perspectival or dialogic cognitive representations) являются уникальными для человеческого вида и играют фундаментальную роль в развитии коммуникативных компетенций в детском возрасте (Томаселло, 2011). В когнитивно-лингвистических исследованиях последних лет было продемонстрировано, что способность человека конструировать и сопоставлять несколько точек зрения (viewpoints) на объекты или события имеет ключевое значение для понимания различных видов коммуникативных сигналов (Sweetser, 2012).
Настоящее исследование показало, что такая способность также играет ключевую роль в обеспечении процессов «нисходящего» совместного внимания человека. С позиции теории концептуальной интеграции Ж. Фоконье и М. Тернера (Fauconnier, Turner, 2002), можно говорить о том, что при восприятии коммуникативной ситуации наблюдатель в реальном времени конструирует ментальные пространства, соответствующие точкам зрения каждого из участников («он видит/думает, что...»). Сопоставление (blending) этих пространств позволяет выделять потенциальные объекты общего внимания участников, которые могут составлять основу (common ground) их будущего коммуникативного взаимодействия. Поддержание в рабочей памяти визуально-пространственных характеристик этих объектов обеспечивает высокую эффективность процессов зрительного внимания наблюдателя при восприятии динамических коммуникативных сцен.
Необходимо отметить, что использованные в настоящей работе социальные ситуации обладают существенным сходством с ситуациями, моделируемыми в задачах на понимание ошибочных убеждений другого человека (false-belief task) в рамках подхода, посвященного изучению так называемой «теории психического» (theory of mind), которая обычно обозначается аббревиатурой ТоМ. В типичной задаче «Салли-Энн» (Sally- Anne test) имеются два персонажа: Салли и Энн. У Салли есть корзинка, а у Энн — коробочка. Салли кладет в корзинку шарик (конфетку и т.п.) и выходит. Энн перекладывает шарик в коробку. Ребенка спрашивают: «Когда вернется Салли, куда она посмотрит? Где она будет искать шарик?» Чтобы предсказать объект внимания Салли, ребенок должен определить ее ошибочное убеждение о местонахождении шарика (Baron-Cohen et al., 1985; Кармилофф-Смит и др., 2012). Сходным образом в нашем исследовании для того, чтобы предсказать объект внимания персонажа ситуации № 1, испытуемый должен определить его ошибочное убеждение о местонахождении «скидочной карты» (см. приведенное выше обсуждение роли выявления ошибок персонажей в прогнозировании объектов их внимания).
Успешное выполнение индивидом задачи на понимание ошибочных убеждений традиционно интерпретируется как свидетельство наличия ТоМ, то есть понимания индивидом того, что другой человек обладает знаниями, убеждениями, намерениями, эмоциями и т. д., отличающимися от его собственных (Baron- Cohen et al., 1985; Сергиенко, 2005; Кармилофф-Смит и др., 2012). Исходя из этого, можно сделать вывод о том, что успешная реализация «нисходящего» совместного внимания в коммуникативных ситуациях требует наличия ТоМ.
В то же время можно согласиться с мнением Е. А. Сергиенко и других авторов о том, что для успешной идентификации ложных убеждений другого человека, необходимой для прогнозирования его поведения (в т.ч. возможных объектов его внимания), недостаточно знания индивида о том, что другой человек обладает убеждениями, намерениями, желаниями и т. д., отличающимися от его собственных. Необходима способность сопоставить точку зрения другого человека со своей собственной позицией или перспективой (Сергиенко, 2005; Sweetser, 2012). Таким образом, с вопроса о том, есть ли у тех или иных контингентов людей (младенцев, больных аутизмом, шизофренией и т.д.) способность к построению ТоМ другого человека, исследовательский акцент смещается на анализ способности людей интегрировать различные точки зрения (multiple viewpoints) на объекты или события. Можно полагать, что продуктивной теоретической основой для изучения данной способности является вышеупомянутая теория Ж. Фоконье и М. Тернера, однако требуются дальнейшие исследования.
Литература
Ахутина Т В., Засыпкина К. В., Романова А. А. Предпосылки и ранние этапы развития речи: новые данные // Вопросы психолингвистики. 2013. Т. 17. №1. С. 20-43.
Бахтин М.М. Эстетика словесного творчества. / Сост. С. Г. Бочаров, примеч. С.С. Аверинцев и С.Г. Бочаров. М.: Искусство, 1979.
Бахтин М.М. Антрополингвистика: Избранные труды. М.: Лабиринт, 2010.
Зотов М. В., Андрианова Н. Е. Быстрое распознание людей на зрительной периферии: данные процедуры «движущегося окна» // Шестая международная конференция по когнитивной науке: Тезисы докладов. Калининград, 23-27 июня 2014 г. Калининград: 2014. С. 300-302.
Ирисханова О. К. Игры фокуса в языке. Семантика, синтаксис и прагматика дефокусирования.М.: Языки славянской культуры, 2014.
Кармилофф-Смит А., Клима Э., Беллуджи У, Ірант Д., Бэрон-Коэн С. Существует ли языковой модуль? Язык, распознавание лиц и теория психического у детей с синдромом Уильямса // Горизонты когнитивной психологии: Хрестоматия / Под ред. В.Ф. Спиридонова, М.В. Фаликман. М.: Языки славянской культуры, 2012. С. 213-230.
Сергиенко Е. А. Революция в когнитивной психологии развития // Российский психологический журнал. 2005. Т. 2. №2. С. 44-60.
Томаселло М. Истоки человеческого общения.М.: Языки славянских культур, 2011.
Фаликман М. В. Внимание. Т. 4 серии «Общая психология» / Под ред. Б.С. Братуся. М.: Академия, 2006.
Akhtar N., Carpenter М., Tomasello М. The role of discourse novelty in early word learning 11 Child Development. 1996. Vol. 67. No.2. P. 635-645. doi:10.2307/U31837
Baron-Cohen S., Leslie A. M., Frith U Does the autistic child have a "theory of mind"? 11 Cognition. 1985. Vol. 21. No. 1. P. 37-46.
Bock S. W., Dicke P., Thier P. How precise is gaze following in humans? 11 Vision Research. 2008. Vol. 48. No. 7. P. 946-957. doi:10.1016/j.visres.2008.01.011
Borji A., Parks D, Itti L. Complementary effects of gaze direction and early saliency in guiding fixations during free viewing 11 Journal of Vision. 2014. Vol. 14. No. 13. P. 3, 1-32. doi: 10.1167/14,13.3
Butterworth G., Jarrett N. What minds have in common is space: Spatial mechanisms serving joint visual attention in infancy // British Journal of Developmental Psychology. 1991. Vol. 9. No. 1. P. 55-72. doi:10.1111/i.2044-835X.1991.tb00862.x
Carpenter M., LiebalK. Joint attention, communication, and knowing together in infancy // Joint Attention: New Developments in Psychology, Philosphy of Mind, and Social Neuroscience. / A. Seemann (Ed.). Cambridge, MA: MIT Press, 2011. P. 159-182.
CerfM., Frady E. P, Koch C. Faces and text attract gaze independent of the task: Experimental data and computer model // Journal of Vision. 2009. Vol. 9. No. 12. P. 10, 1-15. doi: 10.1167/9.12.10
Crouzet S. M., Kirchner EL, Thorpe S. J. Fast saccades toward faces: face detection in just 100 ms // Journal of Vision. 2010. Vol. 10. No. 4. P. 16, 1-17. doi: 10.1167/10.4.16
Emery N.J. The eyes have it: the neuro ethology, function and evolution of social gaze // Neuroscience & Biobehav- ioral Reviews. 2000. Vol. 24. No. 6. P. 581-604. doi:10.1016/ 80149-7634(00)00025-7
Epley N.. Caruso E. M. Perspective taking: Misstepping into others' shoes // Handbook of imagination and mental simulation. / K.D. Markman, W.M.P. Klein, J.A. Suhr (Eds.). N.Y.: Psychology Press, 2008. P. 297-311.
Fauconnier G., Turner M. The way we think: Conceptual blending and the mind's hidden complexities. N.Y.: Basic Books, 2008.
Friesen С. K., Kingstone A. The eyes have it! Reflexive orienting is triggered by nonpredictive gaze // Psychonomic Bulletin & Review. 1998. Vol. 5. No.3. P. 490-495. doi:10.3758/BF03208827
Friesen С. K., Moore C., Kingstone A. Does gaze direction really trigger a reflexive shift of spatial attention? // Brain and Cognition. 2005. Vol. 57. No.l. P. 66-69. doi:10.1016/j. bandc.2004.08.025
Frischen A., Bayliss A. P, Tipper S. P. Gaze cueing of attention: visual attention, social cognition, and individual differences // Psychological Bulletin. 2007. Vol. 133. No. 4. P. 694-724. doi: 10.1037/0033-2909.133.4,694
Komogortsev О. V., Jayarathna S., Koh D. FL, Gowda S. M. Qualitative and quantitative scoring and evaluation of the eye movement classification algorithms // Proceedings of the 2010 Symposium on eye-tracking research & applications. Austin, TX: ACM, 2010. P. 65-68.
Langton S. R., Watt R. J, Bruce V. Do the eyes have it? Cues to the direction of social attention // Trends in Cognitive Sciences. 2000. Vol. 4. No. 2. P. 50-59. doi:10.1016/S1364-6613f99)01436-9
Malcolm G. L., Henderson J. M. The effects of target template specificity on visual search in real-world scenes: Evidence from eye movements // Journal of Vision. 2009. Vol. 9. No. 11. P. 8, 1-13. doi:10.1167/9.11.8
Malcolm G.L., Henderson J.M. Combining top-down processes to guide eye movements during real-world scene search // Journal ofVision. 2010. Vol. 10. No. 2. P. 4,1-11. doi:10.1167/10.2,4
Moll H, Koring C., Carpenter M., Tomasello M. Infants determine others' focus of attention by pragmatics and exclusion // Journal of Cognition and Development. 2006. Vol. 7. No. 3. P. 411-430. doi:10.1207/sl5327647jcd0703 9
Oliva A., Torralha A. Building the gist of a scene: The role of global image features in recognition // Progress in Brain Research. 2006. Vol. 155. P. 23-36. doi:10.1016/S0079-6123(06)55002-2
Risko E. E, Laidlaw К. E., Freeth M., Foulsham T, Kingstone A. Social attention with real versus reel stimuli: toward an empirical approach to concerns about ecological validity // Frontiers in Human Neuroscience. 2012. Vol. 6. P. 143, 1-11. doi:10.3389/fnhum.2012.00143
Shepherd S. V. Following gaze: gaze-following behavior as a window into social cognition // Frontiers in Integrative Neuroscience. 2010. Vol. 4. P. 5, 1-13. doi:10.3389/fnint.2010.00005
Sweetser E. Introduction: Viewpoint and perspective in language and gesture, from the ground down // Viewpoint in language: A multimodal perspective. / B. Dancygier, E. Sweetser (Eds.). Cambridge: Cambridge University Press, 2012. P. 1-23. doi: 10.1017/CBQ9781139084727.002
Todorovic D. Geometrical basis of perception of gaze direction // Vision Research. 2006. Vol. 46. No. 21. P. 3549-3562. doi:10.1016/j.visres.2006.04.011
Tomasello M., Haberl K. Understanding attention: 12-and 18-month-olds know what is new for other persons // Developmental Psychology. 2003. Vol. 39. No. 5. P. 906-912. doi: 10.1037/0012-1649.39.5.906
Walther D., Koch C. Modeling attention to salient protoobjects // Neural Networks. 2006. Vol. 19. No. 9. P. 1395-1407. doi: 10.1016/j.neunet.2006.10.001
Yucel Z., Salah A. A., Merifli (J., Merifli T, Valenti R., Gevers T. Joint attention by gaze interpolation and saliency // Cybernetics, IEEE Transactions on. 2013. Vol. 43. No.3. P. 829-842. doi:10.1109/TSMCB.2012.2216979